Capítulo 7 Gobierno, gestión y calidad del dato
Ismael Caballero\(^{a}\), Ricardo Pérez del Castillo\(^{a}\) y Fernando Gualo\(^{a,b}\)
\(^{a}\)Universidad de Castilla-La Mancha
\(^{b}\)DQTeam SL
7.1 Introducción
Los datos se han convertido en un elemento vital para el desarrollo económico de las organizaciones, ya que permiten una mayor eficiencia en el uso de los recursos y un aumento de su productividad. Tanto es así, que la Unión Europea establece, a través de la Estrategia Europea de Datos,59 que en 2030 se establecerá un Espacio Único Europeo de Datos para fomentar un ecosistema con nuevos productos y servicios basados en los datos. Para ello, en esta Estrategia Europea de Datos –que prevé un incremento del 530% del volumen global de datos– se reclama la necesidad de implantar mecanismos de gobierno del dato a través de políticas y directrices consensuadas a alto nivel para alcanzar los objetivos de la estrategia organizacional y satisfacer tanto aspectos regulatorios genéricos (por ejemplo, las leyes europeas General Data Protection Regulacy –GPDR–60 o Data Governance Act,61 o las españolas Esquema Nacional de Seguridad –ENS–,62 o Esquema Nacional de Interoperabilidad –ENI–63) como aspectos sectoriales específicos (como Solvencia II64 para el sector seguros o Basilea III65 para el sector financiero).
Estos mecanismos de gobierno del dato deben abordar aspectos verticales relacionados con la adquisición, tenencia, compartición, uso y explotación de los datos en los procesos de negocio, abordando a la vez aspectos transversales relacionados con su gestión: calidad de los datos, aspectos éticos y privacidad, interoperabilidad, gestión del conocimiento y el control sobre los activos de datos a través de las políticas correspondientes, y despliegue de estructuras organizativas con una conveniente separación de los roles de gobierno del dato de los de gestión del dato (ISO, 2017). Por tanto, puede decirse que el gobierno del dato marca la dirección de cómo la organización debe realizar la gestión del dato para alcanzar los objetivos establecidos en su(s) estrategia(s) del dato. Esto se consigue mediante la definición e implementación de una serie de políticas del dato.
7.2 Concepto de gobierno del dato
El gobierno de los datos se ha convertido en un habilitador de la economía de los datos (Engels, 2019; Weber et al., 2009), así como también en un pilar básico para la mejora de la transparencia y eficiencia de las administraciones públicas (OECD, 2019; Osimo et al., 2020; Osorio-Sanabria et al., 2020). Aunque existen algunas aproximaciones académicas y profesionales al gobierno del dato, no hay una definición consensuada de este concepto que permita aunar las distintas visiones. No obstante, la definición más aceptada de gobierno del dato es la propuesta por DAMA en DMBoK2 (DAMA, 2017): “colección de prácticas y procesos que ayudan a asegurar la gestión formal de los activos de datos dentro de una organización mediante el ejercicio de autoridad, control y toma de decisiones compartidas, planificadas, monitorizadas y forzadas”. Teniendo en cuenta los matices que introduce, es también interesante la lectura de la propuesta por Soares (2015), que define gobierno del dato como la formulación de políticas para optimizar, conseguir los niveles adecuados de seguridad y protección, y potenciar los datos como activos organizacionales mediante la alineación de los objetivos de diferentes funciones organizacionales; por su naturaleza, el gobierno del dato requiere cooperación interdepartamental para entregar oportuna y fielmente datos con el máximo valor para la toma de decisiones en la organización.
De alguna manera, se podría entender que gobernar los datos implica el diseño, implementación y mantenimiento de un sistema de gobierno del dato. El gobierno del dato tiene tres características destacables (Caballero, Piattini, et al., 2022):
- Está dirigido por el valor de los datos: pues el principal objetivo del gobierno del dato es asegurar que los datos son tratados como activos de datos y que la gestión y uso que se hace de ellos permita alcanzar el máximo valor organizacional que se espera de ellos. Por tanto, todas las acciones están encaminadas a la obtención de este valor organizacional.
- Está centrado en la arquitectura empresarial: para poder gobernar los datos adecuadamente, es preciso revisar o incorporar ciertos componentes a la arquitectura empresarial tales que, o bien den el soporte adecuado, o bien formen parte del resultado del gobierno del dato.
- Es iterativo e incremental, pues para alcanzar un estado en el que se considere que los activos de datos están perfectamente gobernados es preciso desarrollar un conjunto de programas de gobierno del dato. Así, a través de la ejecución de diferentes proyectos relacionados entre sí, se conseguirá el desarrollo y la puesta en valor de los artefactos típicos de un sistema de gobierno del dato (véase Sec. 7.2.2). Esto solo se puede conseguir en incrementos relevantes (por ejemplo, la creación de más componentes del sistema de gobierno del dato o la inclusión de nuevos datos a ser gobernados en el alcance de gobierno del dato).
Un aspecto interesante es que, a medida que se avanza en la ejecución de estos programas de gobierno del dato, más sensible se vuelve la organización hacia la importancia de los datos, más aprende a gestionarlos y gobernarlos y más amplio es el alcance del gobierno del dato; en definitiva, se puede decir que más madura se vuelve la organización en lo que se refiere al gobierno y a la gestión del dato.
7.2.1 Beneficios del gobierno del dato
Cuando se desarrolla un sistema de gobierno del dato, con cada incremento del sistema se espera conseguir uno de los siguientes beneficios o una combinación de los mismos (ISACA, 2019):
Alineamiento estratégico: optimización del valor organizacional de los datos mediante el alineamiento con la estrategia organizacional.
Realización de beneficios: aseguramiento de que los datos son entregados en condiciones aceptables a los diferentes consumidores del dato.
Optimización de riesgos: paliar o minimizar, dentro de la propensión al riesgo de la organización, los riesgos relacionados con la adquisición, uso y explotación de los datos, asegurando el cumplimiento de la normativa interna y regulatoria.
Optimización de recursos: optimización de las capacidades de los recursos humanos y tecnológicos necesarios y que se utilizan para dar un soporte más eficiente a las distintas operaciones involucradas en la gestión del dato, minimizando el desperdicio de recursos al gestionar, usar y explotar los datos.
Estos beneficios deben especificarse como parte de la estrategia del dato de la organización. Así, por ejemplo, una organización que considere realizar un alineamiento estratégico y una optimización de riesgos estará desarrollando una estrategia defensiva que debería implementarse a través de un gobierno técnico; por otro lado, si una organización quiere, por ejemplo, maximizar la realización de beneficios, podría considerarse que estaría trazando una estrategia ofensiva que se podría materializar mediante un gobierno para el valor.
7.2.2 Componentes de un sistema de gobierno del dato
Para poder obtener los beneficios descritos anteriormente, las organizaciones deben implantar los mecanismos de gobierno del dato propuestos en la Estrategia Europea de Datos, particularizándolos a su realidad y en función de su madurez. Estos mecanismos implican el desarrollo de un sistema de gobierno del dato, que involucra la creación o mantenimiento de forma interrelacionada y sujeto a las restricciones correspondientes de una serie de componentes. Dependiendo de si se tiene un gobierno técnico o un gobierno para el valor, la creación y uso de los distintos tipos de componentes será más o menos intensiva. Estos componentes son los siguientes (Caballero, Piattini, et al., 2022):
Procesos de gestión del dato, gestión de calidad del dato y gobierno del dato, que se refieren al diseño y posterior particularización e implantación de las buenas prácticas relacionadas con las tareas típicas de los datos a nivel de las correspondientes disciplinas. Es posible obtener descripciones genéricas de estos procesos en diferentes modelos de referencia de procesos, tales como Data Maturity Model (DMM)(Mecca et al., 2014), The Data Management Capability Assessment Model (DCAM)(EDMCouncil, 2020) o el Modelo Alarcos de Madurez de Datos (MAMD)(Caballero et al., 2023).
Estructuras organizacionales, que deben recoger las cadenas de responsabilidades y rendición de cuentas, haciendo una adecuada separación entre las responsabilidades propias del gobierno del dato y aquellas propias de la gestión del dato y de su calidad. Los roles que deben asumir estas responsabilidades son el de chief data officer (Soares, 2015; Treder, 2020), desde un punto de vista más ejecutivo/estratégico, y los de data stewards (Plotkin, 2020), desde una perspectiva más táctica/operativa.
Principios, políticas y marcos de referencia, que deberían incluir todos los principios rectores en los que se basará el uso de los datos (tales como los generaly accepted information principles listados en Ladley, 2019), las directrices o políticas y los controles correspondientes asociados necesarios para modelar y gestionar el valor de los datos, el riesgo a asumir y las restricciones a considerar según se describe en ISO/IEC 38505-2 (ISO, 2018b).
-
Datos e información, que se deben gobernar como las descripciones necesarias a través de los metadatos correspondientes. Para la parte del dato es fundamental poder establecer una adecuada arquitectura del dato con los correspondientes modelos que recojan la semántica del entorno de la organización y reflejen cómo esta usa los datos para desarrollar su actividad organizacional y/o económica. Para dar soporte al uso correspondiente deben generarse y mantenerse los metadatos correspondientes, que pueden ser de varios tipos (DAMA, 2017):
- metadatos de negocio, normalmente recogidos en el glosario de negocio y que describen la relación del dato con el negocio;
- metadatos técnicos, recogidos habitualmente en los catálogos de datos, que describen detalles técnicos de los datos; y
- metadatos operacionales, que suelen incorporarse en los diccionarios de datos y que recogen aspectos relacionados con el procesamiento y acceso a los datos. Es importante que todos estos metadatos estén reconciliados convenientemente entre ellos, ya que su visión conjunta permitirá una descripción adecuada de los datos bajo el gobierno del dato; y si esta descripción es suficiente será posible usarlos con garantía de éxito.
Cultura, ética y comportamiento, cuyo objetivo es identificar aquellos aspectos culturales y éticos que deben regular la forma en la que la organización abordará las tareas relacionadas con los datos para que estos tengan el valor organizacional deseado (Harrison et al., 2019).
Personas, habilidades y competencias, componente que trata de organizar los roles que deben asumir las diferentes responsabilidades relacionadas con los diferentes procesos; también debe enfocarse en asegurar que esos roles tienen los conocimientos, habilidades y competencias necesarias para abordar las tareas asociadas mediante los programas formativos correspondientes; finalmente, este artefacto incluye asegurar que la organización tiene planes de contingencia ante la eventual rotación funcional de los recursos humanos dedicados a las responsabilidades relacionadas con los datos (Plotkin, 2020).
Servicios, infraestructuras y aplicaciones: este componente aborda todo lo relacionado con las tecnologías y sistemas de información para dar soporte a las diferentes actividades de los procesos de gestión del dato, así como de la gestión de su calidad y de su gobierno.
7.3 Marcos y metodologías de gobierno del dato
En la literatura, tanto académica como profesional, existen algunas propuestas de creación de sistemas de gobierno del dato. Es interesante resaltar que en el ámbito académico se han desarrollado algunas revisiones sistemáticas de literatura científica para identificar los componentes del gobierno del dato, aunque de forma general, y salvo algunas referencias, se mantienen desconectados de las propuestas profesionales. También es importante mencionar que salvo COBIT 2019 (Control Objectives for Information and Related Technology, objetivos de control para la información y tecnologías relacionadas),66 la inmensa mayoría de estos marcos no identifican explícitamente el concepto de sistema de gobierno del dato, sino que se establece bajo un paraguas más genérico de gobierno del dato. En cualquier caso, la idea es la misma.
En los siguientes párrafos se resumen los aspectos más importantes de los marcos más relevantes, que pueden servir para que el lector encuentre el que mejor se adapta a su circunstancia profesional:
Abraham et al. (2019) analizan la literatura para identificar los elementos de un marco de trabajo teórico, que se clasifican en torno a cuatro áreas del gobierno del dato: (1) alcance organizacional (aspectos intra e interorganizacionales), (2) alcance de los datos (datos tradicionales vs. big data), (3) alcance del dominio (calidad del dato, seguridad del dato, arquitectura del dato, ciclo de vida, metadatos, almacenamiento e infraestructura del dato) y (4) mecanismos de gobierno (estructurales, procedimentales y relacionales).
Al-Ruithe et al. (2019) identifican, también a través de una revisión sistemática de literatura, las áreas o retos del gobierno del dato donde merece la pena investigar. Estas son tecnología (seguridad, privacidad, disponibilidad, rendimiento, clasificación de los datos y migración del dato), legalidad, y aspectos organizacionales o del negocio.
Brous et al. (2016) derivan, de nuevo basándose en una revisión sistemática de la literatura, los principios para desarrollar de forma efectiva estrategias y aproximaciones para el gobierno del dato, que agrupan en torno a cuatro conceptos fundamentales: (1) organización, (2) alineamiento, (3) cumplimiento y (4) entendimiento común de los datos.
Carruthers & Jackson (2020) identifican los posibles elementos que deben contemplarse en la transformación digital, la cual debe apoyarse en el gobierno del dato. Estos elementos (personas, datos, procesos, tecnologías) son representados mediante un triángulo en cuyo centro están los datos. En la continuación de este trabajo (Jackson & Carruthers, 2019), se propone un modelo de transformación convenientemente soportado en el gobierno del dato.
DCAM (data management capability assessment model) (EDMCouncil, 2020) es un modelo de referencia para la evaluación de la capacidad de gestión del dato desarrollado por el EDM Council. El modelo tiene ocho componentes agrupados en cuatro niveles: (1) fundamentos (estrategia del dato y casos de negocio; programas de gestión del dato y financiación), (2) ejecución (arquitectura del dato y de negocio; arquitectura del dato y de tecnología; gestión de calidad del dato; gobierno del dato), (3) colaboración (entorno de control del dato) y (4) formalización del diseño e implementación de las actividades analíticas.
DMBoKv2 (data management body of knowledge) (DAMA, 2017) es un marco de referencia de procesos desarrollado por DAMA que posiciona el gobierno del dato como la función que guía el resto de las acciones relacionadas con la gestión del dato. Identifica una serie de elementos que deben generarse a partir del gobierno del dato: estrategia de gobierno del dato; estrategia del dato; hoja de ruta del gobierno del dato; principios de gobierno del dato, políticas de gobierno del dato; procesos; marco operativo de gobierno del dato; hoja de ruta y guía de implementación; plan de operaciones; glosario de términos; plan de operaciones; cuadro de mando de gobierno del dato; etc.
Eryurek et al. (2021) identifica los “ingredientes” propios de un sistema de gobierno del dato (herramientas; personas y procesos; cultura del dato), así como las áreas en las que debería enfocarse el gobierno de datos a lo largo del ciclo de vida de los datos (descubrimiento y limpieza del dato; gestión del dato; políticas de privacidad, seguridad y acceso).
COBIT 2019 (ISACA, 2019) identifica los siguientes componentes en el sistema de gobierno de tecnologías y de información: procesos; estructuras organizacionales; principios, políticas y marcos de referencia; información; cultura, ética y comportamiento; personas, habilidades y competencias; y servicios, infraestructuras y aplicaciones.
ISO 38505-1 (ISO, 2017) e ISO 38505-2 (ISO, 2018b) muestran los aspectos clave del gobierno del dato (valor de los datos, riesgo y restricciones) e introducen seis principios (responsabilidad, estrategia, adquisición, rendimiento, cumplimiento y comportamiento humano). Identifican una serie de procesos (evaluar, dirigir, monitorizar) como áreas propias de actuación del gobierno del dato, distinguiéndolos de las operaciones propias de la gestión del dato y estableciendo las correspondientes relaciones con ellas. Sin embargo, no describen actividades específicas para la creación de sistemas de gobierno del dato.
Khatri & Brown (2010) aducen que el gobierno del dato implica tomar decisiones sobre activos claves de datos en varios dominios de decisión (principios, gestión de calidad del dato, metadatos, acceso a datos y ciclo de vida de los mismos).
Janssen et al. (2020) exploran las capacidades de gobierno del dato necesarias para que las organizaciones dirigidas por datos puedan extraer el máximo beneficio de los sistemas algorítmicos basados en big data (big data algorithmic systems) y proponen un marco para la creación del gobierno del dato que permita optimizar estos sistemas.
Ladley (2019) presenta un marco de gobierno del dato basado en cinco pilares: compromiso, estrategia, arquitectura y diseño, implementación y operación, y, por último, gestión del cambio.
Lillie & Eybers (2019) estudian la literatura existente para identificar los aspectos más interesantes sobre (1) el alcance y los constructos más importantes del gobierno y gestión del dato, y (2) las capacidades ágiles requeridas en el gobierno y la gestión de datos.
En el llamado proceso Unificado de Gobierno del dato de IBM (Soares, 2010) se identifican cinco ingredientes clave que deberían ser cubiertos por cualquier marco de gobierno del dato: (1) fuerte respaldo por parte de la organización con soporte de las TI, (2) centrarse en los elementos de datos críticos, (3) énfasis en los artefactos de datos, (4) alineación en torno a métricas y aplicación de políticas, y (5) celebración de las victorias rápidas conseguidas como hitos en una hoja de ruta a largo plazo.
La Organización para la Cooperación y el Desarrollo Económicos (Organisation for Economic Cooperation and Development, OECD), en su informe sobre gobierno del dato para administraciones públicas (OECD, 2019), recoge las mejores prácticas llevadas a cabo por diferentes administraciones de los países que la componen en lo que se refiere a transparencia del gobierno del dato e incremento del valor de la información disponible sobre la ciudadanía de cara a una mejor prestación de servicios públicos.
Treder (2020) identifica algunos componentes específicos que debería tener un sistema de gobierno del dato (cadenas de valor; estrategia de dato; procesos de datos; descripción de los roles y sus responsabilidades; gestión del equipo de la oficina del dato), así como las áreas en las que debe enfocarse el gobierno del dato (casos de negocio; aspectos éticos y cumplimiento; gestión y análisis del dato).
A modo de ejemplo, se dan más detalles sobre un marco de referencia basado en estándares internacionales ISO: el Modelo Alarcos de Madurez de Datos (MAMD) v4.0 (Caballero et al., 2023). MAMD v4.0 es un marco de trabajo que se usa para la evaluación y mejora de la capacidad de los procesos de la organización relacionados con la gestión, la gestión de la calidad, y el gobierno del dato. Tiene dos componentes principales:
- Un modelo de referencia de procesos (MRP), que contiene una descripción de los procesos de gestión del dato, de gestión de calidad del dato y de gobierno del dato. Está alineado con los principales estándares en el área: ISO 8000-61 (ISO, 2016), e ISO/IEC 38505-2 (ISO, 2018b), así como con las buenas prácticas de otros modelos como DAMA, DMM o COBIT 2019 (véase Fig. 7.1).
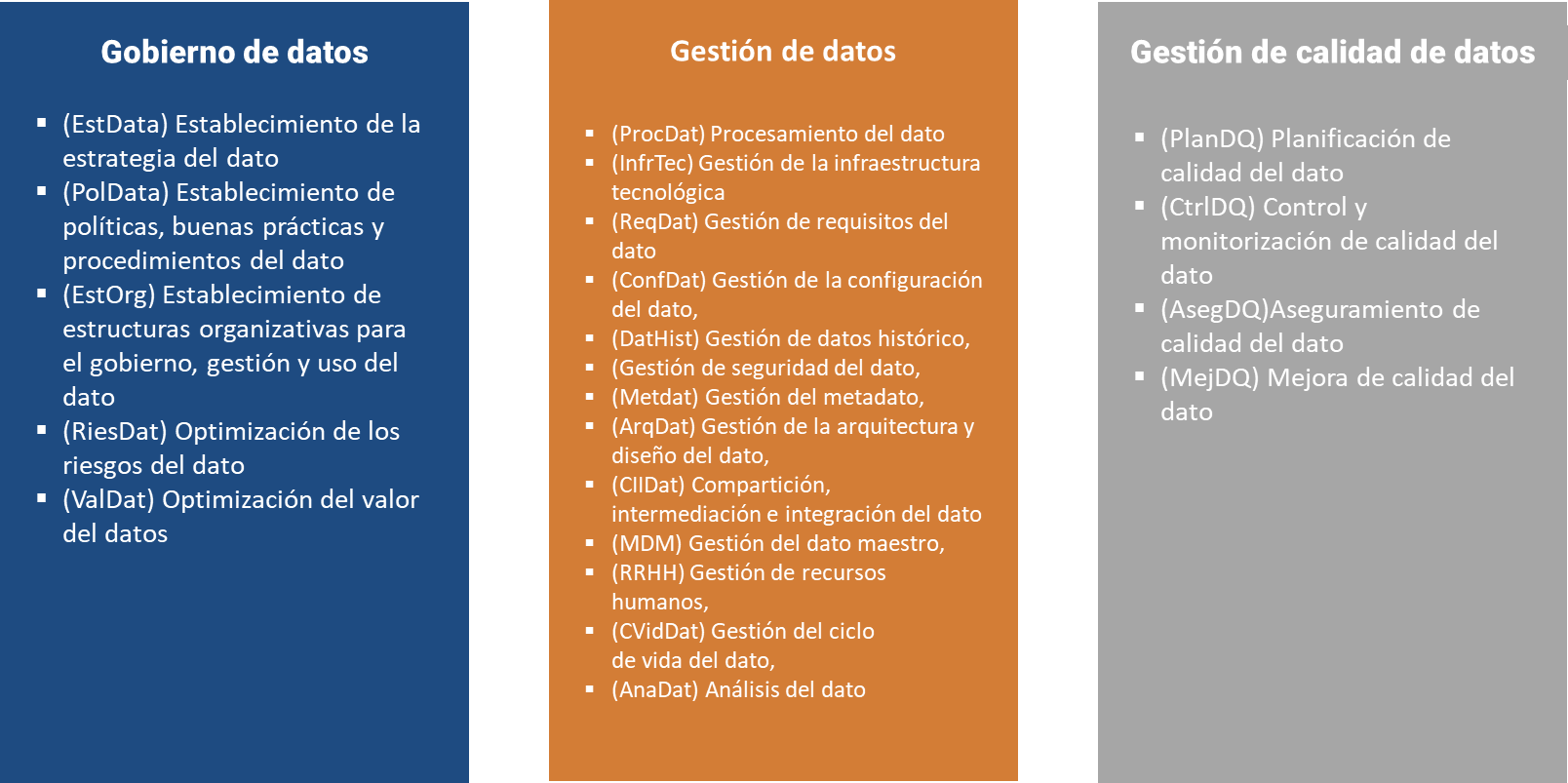
Figura 7.1: Modelo de referencia de procesos de MAMD. DM: gestión del dato; DQM: gestión de calidad del dato; DG: gobierno del dato.
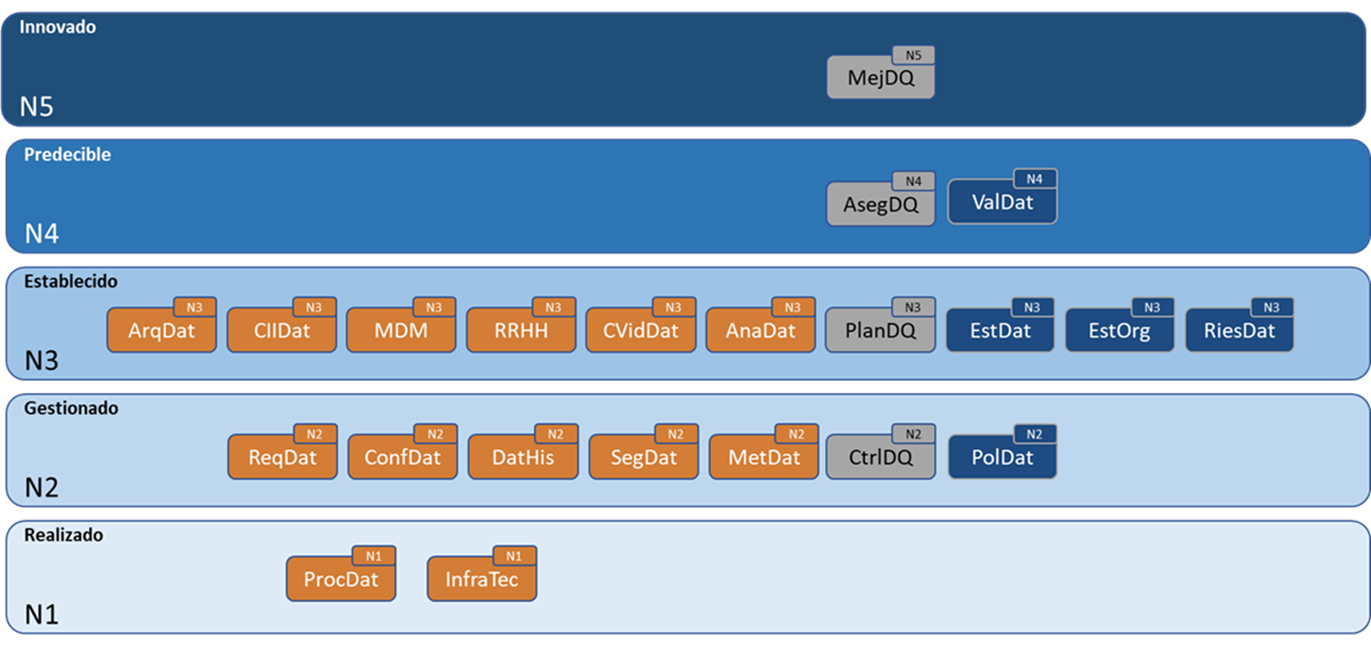
Figura 7.2: Modelo de madurez organizacional de MAMD; N: nivel; DM: gestión del dato; DQM: gestión de calidad del dato; DG: gobierno del dato.
- El modelo de evaluación de procesos (MEP), que sigue las directrices de evaluación y los niveles de capacidad y madurez descritos por ISO/IEC 33000 y adaptados a la evaluación de procesos de datos conforme al modelo de madurez propuesto en ISO 8000-62 (ISO, 2018a) (véase Fig. 7.2).
7.4 Gestión de calidad del dato
Los datos con niveles inadecuados de calidad acaban teniendo un impacto negativo para las organizaciones, bien en términos económicos, bien en términos de reputación (Redman, 2016). Por eso es importante que las organizaciones cuiden del nivel de calidad de sus datos y se aseguren de que dicho nivel permanece dentro de los permitidos para que la ejecución de los procesos de negocio se haga dentro del margen de riesgo de la organización.
Se dice que un conjunto de datos tiene calidad cuando sirve para el propósito para el que fue recogido (fitness for use) (Strong et al., 1997b). Para determinar si un conjunto de datos tiene calidad suficiente para dicho propósito es preciso identificar y seleccionar un conjunto de criterios –llamados en la literatura dimensiones (Wang, 1998) o características de calidad del dato (ISO/IEC, 2012)– que permitan determinar si dicho conjunto cumple los requisitos de calidad que exige el usuario de tales datos. Al conjunto de dimensiones o características de calidad del dato seleccionadas se le denomina modelo de calidad del dato. La Tabla ??67 muestra una descripción de las características de calidad del dato incluidas en el estándar ISO/IEC 25012.
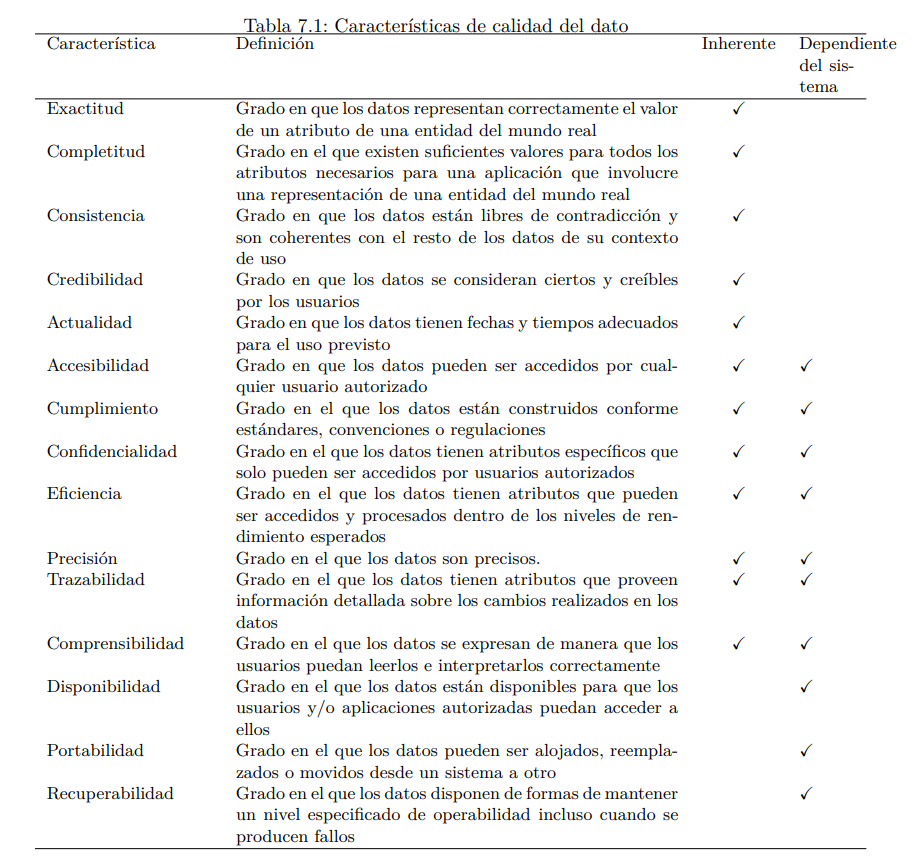
Como puede observarse, estas características se clasifican en dos grandes bloques: inherentes y dependientes del sistema. Las inherentes se refieren al grado con el que las características de calidad de los datos tienen un potencial intrínseco para satisfacer las necesidades establecidas y necesarias cuando los datos son utilizados bajo condiciones específicas; las dependientes del sistema permiten determinar el grado con el que la calidad del dato es alcanzada y preservada a través de un sistema informático cuando los datos son utilizados bajo condiciones específicas.
Para ilustrar el significado de algunas de estas características (por ejemplo, exactitud, completitud o consistencia). A continuación se exponen algunos ejemplos:
- Como ejemplo de nivel inadecuado de exactitud sintáctica podría ponerse el hecho de que el atributo
Nombrede la entidadPersonatomase un valor o dato “Marja” (no existente en los datos de referencia de nombre) en lugar de “María” (que sí que está incluido). - El hecho de que el atributo
Nombrede la entidadPersonatome el valor de “George” en vez de “Jorge” para almacenar datos de la persona llamada realmente “Jorge” es un ejemplo de nivel inadecuado de exactitud semántica. Ambos valores son sintácticamente correctos, peroGeorgees otra persona distinta aJorge, y quien capturó y guardó los datos simplemente se equivocó de persona. - Supóngase que, para una determinada aplicación, se necesita recoger valores (o datos) para los siguientes atributos de una entidad Persona:
DNI,Nombre,Apellido1, yApellido2para ser empleados adecuadamente en un contexto de uso. En caso de faltar alguno de ellos (nivel inadecuado de completitud), podría ocurrir que los datos de la persona no se pudieran utilizar; incluso podrían faltar algunos atributos más, como por ejemploemail, pero si no es relevante para la aplicación, no habría ese problema de completitud. - Un ejemplo de falta de consistencia puede darse, por ejemplo, cuando el valor (o dato) del atributo
FechaNacimientode la entidad Persona es posterior a la fecha de hoy.
Diferentes autores han proporcionado diferentes mecanismos para medir y evaluar la calidad de los datos usando las dimensiones o características de calidad seleccionadas. Aunque para dar soporte a este proceso se han propuesto numerosas metodologías de evaluación (Batini et al., 2016), el principal problema de estas contribuciones es que, normalmente, se han realizado ad hoc y no permiten ni generalizar los resultados obtenidos ni compararlos con los obtenidos por otras organizaciones (Loshin, 2011).
Para paliar estos problemas, se han desarrollado estándares que recogen los conocimientos y principios básicos comunes para medir y evaluar la calidad de los datos. Ejemplos de estos estándares pueden ser la mencionada ISO/IEC 25012 (ISO/IEC, 2012) y la ISO 8000-8 (ISO/IEC, 2015), que recogen características de calidad; la ISO/IEC 25024 (ISO/IEC, 2008), que recoge aspectos específicos de cómo llevar a cabo las mediciones de las características; o la ISO/IEC 25040 (ISO/IEC, 2011), que proporciona una metodología de evaluación de calidad del software que puede ser adaptada a la evaluación rigurosa y sistemática de la calidad de los datos. En este punto es necesario introducir la principal diferencia entre medir y evaluar la calidad: medir consiste en determinar la cantidad de calidad del dato que tiene un conjunto de datos; evaluar implica determinar si, de acuerdo al nivel de riesgo que asume la organización, la cantidad de calidad del dato medida es suficiente y adecuada para usar los datos en el contexto de uso establecido para esos datos. La evaluación de calidad del dato requiere primero medir la calidad; y para medir la calidad, primero deben definirse procedimientos de medición.
En ese sentido, ISO 25024 (ISO/IEC, 2008) proporciona una serie de propiedades medibles para cada una de las características presentadas en la Tabla ??; además, para cada una de estas propiedades medibles, el estándar proporciona un método de medición genérico que permitirá, convenientemente particularizado, medir dichas propiedades y luego agruparlas para determinar el valor de la característica de calidad del dato. La Fig. 7.3 muestra las propiedades medibles para las características de calidad identificadas como inherentes (véase Tabla ??).
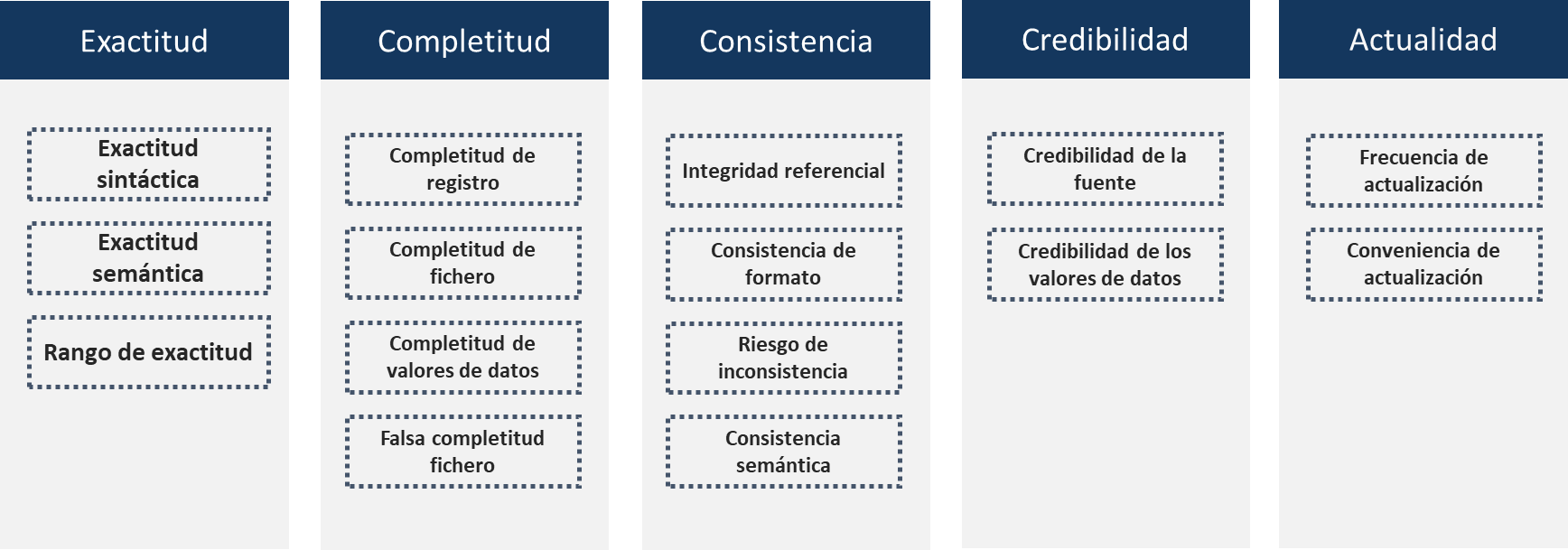
Figura 7.3: Algunas propiedades de las características inherentes de calidad del dato.
Una de las ventajas de usar estas propiedades medibles es que, en caso de niveles inadecuados de calidad de datos, es posible identificar mejor qué está causando que esto ocurra y, por tanto, es más fácil actuar directamente sobre dichas causas.
A modo de ejemplo, supóngase que se quiere medir el grado de exactitud de un conjunto de datos. Para ello se considera necesario medir las propiedades exactitud sintáctica, exactitud semántica y rango de exactitud. Con lo resultados de la medición habrá que hacer algún tipo de agrupación que tenga en cuenta la importancia o peso relativo de cada una de estas propiedades a la hora de evaluar la exactitud. Supóngase que una organización determina que la mejor forma de hacerlo es mediante una media aritmética ponderada de los resultados de la medición de las tres propiedades medibles. En base a su nivel de riesgo para un determinado proceso de negocio, supóngase que la organización considera que, para una determinada aplicación, puede asignar, para la media aritmética ponderada, los siguientes pesos: 0,4; 0,4 y 0,2 para la exactitud semántica, para la exactitud sintáctica y para el rango de exactitud respectivamente.
A la hora de medir las propiedades medibles correspondientes a las características de calidad del dato, es interesante tener en cuenta que la ISO/IEC 25024 proporciona procedimientos de medición cuya implementación depende fuertemente de la naturaleza de la propiedad y del objeto cuya calidad quiere medirse. La medición de algunas de estas propiedades implica contar el porcentaje de registros que violan las reglas de negocio que regulan la adecuación al uso de los datos en un contexto determinado (Loshin, 2002). Sin embargo, a la hora de la medición, uno de los ejercicios más difíciles es recolectar y validar las reglas de negocio específicas que rigen la validez de los datos (Caballero, Gualo, et al., 2022).
Para el ejemplo propuesto, imagínese que si se pretende medir el nivel de exactitud sintáctica del dato recogido en el atributo DNI se pudiera usar la siguiente regla de negocio “el DNI tiene que seguir la especificación para DNI, o para el NIE, correspondiente con la expresión regular (d{8})([A-Z])”. Habría que comprobar bien manualmente, bien mediante algún tipo de script, cuántos registros verifican la anterior regla de negocio para el atributo DNI.
Supóngase que, para el ejemplo, y tras haber realizado todas las mediciones de las propiedades y haberlas agrupado realizando la media aritmética ponderada, se obtiene una exactitud de 70.
Una vez realizada la medición, el siguiente paso es la evaluación propiamente dicha. La evaluación consiste en comparar el resultado obtenido (70 en el ejemplo) con el umbral mínimo de aceptación, que depende del nivel de riesgo que decida asumir la organización al utilizar estos datos (Redman, 2016). Si, por ejemplo, dicho umbral se hubiese establecido en 75 para el uso concreto que se le va a dar a estos datos, se concluiría que no deberían ser utilizados. Esto no significa que los datos no puedan usarse en otro contexto en el que, por ejemplo, el valor umbral se estableciese en 65.
Como se verá posteriormente en el Cap. ??, en algunos contextos de uso antes de usar los datos se realiza un proceso de preparación de los mismos que tiene como objetivo determinar y adecuar los niveles de calidad al uso que se pretende dar mediante un proceso de evaluación y mejora que se centra en la limpieza de los datos. Normalmente, en este proceso suele recurrirse a métodos estadísticos, frente a la aproximación basada en la medición de las características de calidad del dato presentada anteriormente. Se pierde entonces, de alguna manera, la capacidad de establecer una dirección más efectiva y, sobre todo, alineada a las necesidades reales de la organización, de las operaciones de evaluación y limpieza del dato.
Finalmente, es interesante mencionar que, basándose en los estándares ISO/IEC 25012 (ISO/IEC, 2012) e ISO/IEC 25024 (ISO/IEC, 2008), es posible certificar el nivel de calidad del dato de un repositorio de datos. En Gualo et al. (2021) se recogen experiencias de medición, evaluación y certificación de calidad del dato a este respecto.
7.4.1 Medición de calidad de datos vs. perfilado del dato
En esta subsección se plantea el perfilado del dato como una técnica base para realizar la medición de las propiedades medibles de las características de calidad del dato o para descubrir nuevas reglas de negocio.
El perfilado de datos es el conjunto de actividades y procesos que sirve para obtener algunos metadatos (incluyendo reglas de negocio) de un conjunto de datos. Estos metadatos pueden usarse como base para realizar la medición de las propiedades medibles de las características de calidad del dato.
Abedjan et al. (2015) clasifican los tipos de perfilado del dato en las siguientes categorías:
Perfilado de columna simple, que implicaría tareas de identificación de cardinalidades, identificación de patrones y tipos de datos, distribución de valores de datos, clasificación de dominios.
Perfilado de columnas múltiples, que implicaría tareas de correlación y reglas de asociación, identificación de clústeres y outliers, elaboración de resúmenes de datos y bocetos.
-
Perfilado de dependencias, que a su vez implica:
- Detección de reglas de unicidad, tales como la identificación de claves, identificación de condiciones e identificación de sinónimos.
- Detección de dependencias de inclusión, que puede abarcar el descubrimiento de claves ajenas o la identificación de dependencias condicionales de inclusión.
- Dependencias funcionales, como pueden ser las dependencias condicionales.
En R software el paquete dlookr (Ryu, 2022) contiene algunas funciones interesantes para llevar a cabo determinadas tareas de perfilado.
Por ejemplo, la función overview() da información general sobre un conjunto de datos; resulta muy interesante la función diagnose(), que proporciona información realizando un perfilado de los valores únicos y los valores únicos de un conjunto de valores.
El siguiente fragmento de código (chunck) mostraría, si se ejecutase el tipo de información proporcionada por diagnose (Madrid_POIS$City_Center): variables muestra el nombre de los atributos del conjunto de datos (en este caso Londe longitud y Lat de latitud); types muestra el tipo de dato de cada variable; missing_count, missing_percent, unique_count y unique_rate describen respectivamente el conteo de valores nulos, el porcentaje de dichos valores, el número de valores únicos o no repetidos y su correspondiente porcentaje; <chr>, <int>, <dbl> se hacen referencia al tipo de dato de cada uno de los parámetros anteriores (carácter, integer, double).
library("dlookr")
library("idealista18")
diagnose(Madrid_POIS$City_Center)Si estas funciones de perfilado proporcionan información suficiente y adecuada, es posible usar los resultados para computar las mediciones de las propiedades medibles.
Por ejemplo, se puede utilizar el resultado de la columna missing count para calcular el grado de completitud de las variables longitud y latitud, que se pueden establecer en 100% al ser missing count = 0 para las dos variables.
Incluso se pueden utilizar funciones como plot_na_pareto() para visualizar un gráfico de Pareto que muestre las variables que no tienen valores nulos.
Finalmente, es interesante mencionar que el paquete dlookr incluye funciones como diagnose_paged_report(), que permiten elaborar informes que contienen información sobre las estructuras de datos del conjunto de datos, avisos, descripción de las variables, valores perdidos, valores únicos de las variables categóricas y numéricas, distribuciones de valores nulos y negativos, posibles valores atípicos (outliers), etc.
El siguiente fragmento de código muestra cómo crear un informe de 15 páginas en formato PDF con toda esa información sobre la variable idealista18::Madrid_POIS$Metro :
#diagnose_paged_report(idealista18::Madrid_POIS$Metro)En ocasiones, y retomando la idea de las reglas de negocio, cabe decir que la información proporcionada por el perfilado del dato puede usarse para \((i)\) derivar reglas de negocio a partir del estado actual de los datos y \((ii)\) recoger información que se puede emplear durante el proceso de medición de determinadas características de calidad del dato.
En el Cap. ?? se profundizará en el proceso de estudio de dos características de calidad del dato: completitud y consistencia.
7.4.2 Mejora del dato
Si los datos no tienen el nivel de calidad necesario, es preciso mejorar su calidad para que no arruinen los procesos de negocio.
Para ello, a partir de los resultados de las mediciones, los analistas de calidad del dato deben determinar las causas raíz de esos niveles inadecuados de calidad del dato.
Strong et al. (1997a) identifican diez posibles obstáculos que pueden hacer que los datos no tengan esos niveles adecuados de calidad:
- Múltiples fuentes de datos producen diferentes valores para el mismo atributo de la misma entidad.
- La realización de juicios subjetivos en la producción de los datos puede llevar a valores diferentes.
- Errores sistemáticos en la producción de información llevan a la pérdida de información.
- Grandes volúmenes de información almacenada dificultan su acceso en tiempo razonable.
- Sistemas heterogéneos distribuidos llevan a definiciones, formatos y valores inconsistentes.
- La información no numérica es difícil de indexar.
- El análisis automatizado de los contenidos en colecciones de información puede no producir resultados adecuados.
- A medida que las necesidades de los usuarios cambian, la información que es relevante y útil para la realización de una determinada tarea también cambia.
- Un acceso fácil a la información puede entrar en conflicto con los requisitos de seguridad, confidencialidad y privacidad.
- La falta de recursos de computación limita el acceso a los datos en circunstancias favorables.
Lógicamente, la naturaleza del problema detectado determina las acciones correctivas que de deben llevar a cabo. En todo caso, dichas acciones se pueden encuadrar en uno de los dos siguientes tipos:
Corrección de causas sistemáticas. Si se observa que los problemas se suceden de forma sistemática y repetida, entonces las acciones de mejora del dato deben estar orientadas a eliminar esas causas sistemáticas (véase Strong et al., 1997a). Por ejemplo: si los errores de calidad del dato se deben a que un proceso de negocio está mal diseñado, entonces hay que rediseñarlo; si las causas se deben a que hay personas desempeñando ciertos roles para los que no tienen los conocimientos o habilidades adecuadas, entonces hay que darles la formación adecuada; o si se deben a que hay software (por ejemplo, procesos ETL) que falla, entonces hay que realizar el mantenimiento correctivo correspondiente en dicho software.
Corrección de errores debidos a causas aleatorias. Si no es posible identificar cuáles son las causas raíz, porque son completamente desconocidas o aleatorias, no queda más remedio que actuar sobre los valores de los datos, cambiándolos para asegurar que cumplen las reglas de negocio establecidas. A este proceso se le suele llamar depuración o limpieza de datos (data cleansing). Ilyas & Chu (2019) identifican diversas técnicas de limpieza de datos (que pueden incluir operaciones de imputación de datos como las incluidas en la Sec. 8.3.4 del Cap. ??: limpieza basada en reglas de negocio, de duplicación de datos, transformación de datos, o guiada por machine learning (véanse Caps. ?? y 9). En este caso, sería posible utilizar algunas funciones del paquete
dlookrrelacionadas con la transformación de los datos, comoimputate_na()oimputate_outlier(), que generan valores para los datos faltantes o valores que garantizan niveles adecuados de exactitud o de consistencia.
Resumen
En este capítulo se presentan los fundamentos del gobierno del dato. Es importante tener en cuenta los siguientes aspectos:
El gobierno del dato tiene como objetivo asegurar que los datos que se usan y gestionan en las organizaciones están alineados con las estrategias del dato de la organización, maximizando así su valor organizacional.
Gobernar los datos implica el diseño, implementación y mantenimiento de un sistema de gobierno del dato. Un sistema de gobierno del dato tiene siete tipos de componentes: procesos de gestión del dato, gestión de calidad del dato y gobierno del dato; estructuras organizacionales; principios, políticas y marcos de referencia; datos y descripción de los datos; cultura, ética y comportamiento; personas, habilidades y competencias; servicios, infraestructuras y aplicaciones.
Existen modelos de referencia que pueden ser usados como base para la creación de sistemas de gobierno del dato.
El gobierno del dato persigue cuatro beneficios básicos para la organización: alineamiento estratégico, realización de beneficios, optimización de riesgos, optimización de recursos.
La gestión de la calidad del dato es el proceso mediante el cual se garantiza que los datos tengan el nivel de calidad adecuado para las tareas para las que fueron recogidos.
Para evaluar y medir la calidad se necesitan criterios; estos criterios se llaman características o dimensiones de calidad del dato.
La evaluación y medición de calidad del dato requiere la identificación y clasificación de las reglas de negocio que rigen la validez de los datos. Las técnicas y herramientas de perfilado del dato se pueden utilizar como base para la identificación de reglas de negocio a partir de los datos.
Cuando las mediciones y evaluaciones realizadas indican que los datos no tienen calidad, deben investigarse cuáles son las posibles causas. Si las causas son sistemáticas hay que enfocar el problema desde un punto de vista organizacional; si son aleatorias se pueden usar las técnicas de limpieza de datos.