Capítulo 6 Gestión de bases de datos NoSQL
Ricardo Pérez-Castillo\(^{a}\) e Ismael Caballero\(^{a}\)
\(^{a}\)Universidad de Castilla-La Mancha
6.1 Introducción al big data
Actualmente se vive en la era de la información, con un teléfono móvil en cada bolsillo, un ordenador portátil en cada mochila y grandes sistemas de tecnología funcionando diariamente mandando datos y datos cada segundo. El mundo tiene más datos que nunca, pero esto no es todo, ya que el volumen aumenta de forma exponencial (López, 2012). Es la era de las bases de datos masivos, en inglés big data.
En particular, el volumen de datos disponibles para las empresas aumentó drásticamente desde 2004. En 2004, la cantidad total de datos almacenados en Internet fue de 1 petabyte (equivalente a 100 años de todo el contenido de televisión). En 2011 la cantidad total de información almacenada en todo el mundo ya era de 1 zettabyte (1 millón de petabytes o 36 millones de años de vídeo de alta definición); en 2015 alcanzó los 7,9 zettabytes (o 7,9 millones de petabytes) y en 2020 se disparó a 35 zettabytes (o 35 millones de petabytes). Este gran volumen de datos, y su crecimiento continuo y exponencial, supera las capacidades de las herramientas de datos tradicionales para capturarlos, almacenarlos, administrarlos y analizarlos (Kalyvas & Overly, 2014). Por este motivo, se hace necesario el uso de nuevos métodos, técnicas y herramientas de gestión de datos. Este espacio es el que cubre big data.
Big data es un término abstracto que, en cierta medida, se ha puesto de moda en diferentes ámbitos: negocios, marketing, social media y diferentes ingenierías como la informática, sistemas de información, almacenamiento y recuperación de datos, etc. Big data es un término que hace referencia al gran volumen de datos (tanto estructurados como no estructurados) que inundan día a día a cualquier organización. Pero lo más relevante no es la cantidad de datos. Lo que realmente importa es lo que las organizaciones pueden hacer con los datos. Los grandes volúmenes de datos se pueden analizar, por ejemplo, en busca de ideas conducentes a una mejor toma de decisiones y movimientos comerciales estratégicos (SAS Institute, 2017).
Cuando se acumulan grandes volúmenes de datos, se plantea la necesidad de ver qué se puede hacer con ellos. Esto implica gestionar los datos con una finalidad organizativa y disponer de tecnología y metodologías específicas. La propia gestión de datos lleva a generar información relevante en el contexto de la organización, es decir, a generar conocimiento para la acción que sea aplicable: por ejemplo, a la toma de decisiones, al diseño de acciones o a la elaboración de planes estratégicos (García-Alsina, 2017).
Por tanto, cuando se habla de datos masivos, se está hablando también de gestión de la información y de generación de conocimiento para la acción. Este campo científico es el que proporciona las pautas metodológicas para gestionar grandes volúmenes de datos con el fin de crear valor mediante una serie de procesos y procedimientos. Pero exige contar con la tecnología para capturar los datos, procesarlos, analizarlos e interpretarlos de manera eficaz y eficiente (García-Alsina, 2017; Gómez García et al., 2015).
Por consiguiente, se puede concluir que big data es el “conjunto de datos masivos heterogéneos que supera la capacidad del software habitual para ser capturados, gestionados y procesados en un tiempo razonable”. Esta definición tiene en cuenta tres de las V del big data (véase Sec. 6.2): volumen, variabilidad y velocidad. Así, cuando se habla de big data se está haciendo referencia a conjuntos de datos o combinaciones de conjuntos de datos cuyo tamaño (volumen), complejidad (variabilidad) y velocidad de crecimiento dificultan su captura, gestión, procesamiento y análisis mediante tecnologías y herramientas convencionales, tales como las bases de datos relacionales y los paquetes de visualización y técnicas estadísticas convencionales, en el tiempo necesario para que sean útiles.
6.2 Las V del
El volumen se refiere a la cantidad de datos que son generados cada segundo, minuto y día en nuestro entorno. Es la característica más asociada al big data, ya que hace referencia a las cantidades masivas de datos que se almacenan con la finalidad de procesar dicha información, transformando los datos en acciones. Las personas están cada vez más conectadas al mundo digital, por lo que se generan más y más datos. Para algunas empresas, el estar en el mundo digital es algo obligatorio, por lo que la cantidad de datos generados es aún mayor. Por ejemplo, a una empresa que vende sus productos únicamente a través de un canal online, le convendría implantar tecnología big data para procesar toda aquella información que recoge su página web rastreando todas las acciones que lleva a cabo el cliente: conocer donde cliquea más veces, cuántas veces ha pasado por el carrito de la compra, cuáles son los productos más vistos, las páginas más visitadas, etc.
La velocidad se refiere a la rapidez con la que los datos son creados, almacenados y procesados en tiempo real. Así, en procesos como la detección de fraude en una transacción bancaria o la monitorización de un evento en redes sociales, el tratamiento de la información en tiempo real es imprescindible para que resulten útiles y den lugar a acciones efectivas. Otros ejemplos son la gestión de catástrofes naturales o pandemias, o el seguimiento de una campaña analizando comentarios de los actores a quienes esta va dirigida, para ir reorientándola en función de la retroalimentación que fluye en redes sociales (García-Alsina, 2017).
La variedad se refiere a que los sistemas de procesamiento del big data deben ser capaces de procesar datos de diversas formas, tipos y fuentes. Los datos pueden ser estructurados y fáciles de gestionar, como las bases de datos relacionales, o no estructurados, entre los que se incluyen desde documentos de texto, correos electrónicos, datos de sensores, audios, vídeos o imágenes que se tienen en un dispositivo móvil hasta publicaciones en los perfiles de redes sociales, artículos en blogs, secuencias de clic que los usuarios hacen en una misma página, formularios de registro e infinidad de acciones más que se realizan desde un smartphone, una tablet o un ordenador. Este tipo de datos requiere un herramental específico, ya que su tratamiento es totalmente diferente al de los datos estructurados. Por ello, las empresas necesitan disponer de las herramientas apropiadas para integrar, observar y procesar este tipo de datos.51
Con el tiempo, se han ido incorporando, progresivamente, otras V: las V de valor (de enorme interés en el análisis de datos), veracidad, viabilidad y visualización (IIC, 2016).
6.3 Tipos de datos en entornos
En función de la estructura con la que se organizan los datos (forma en la que se agrupan, almacenan y se relacionan entre sí y manera en la que se puede acceder a ellos, analizarlos o modificarlos), estos pueden clasificarse en: estructurados, no estructurados o semiestructurados.
Datos estructurados: son aquellos que tienen longitud y formato, como las fechas, los números o las cadenas de caracteres. En esta categoría entran los que se compilan en los censos de población, los diferentes tipos de encuestas, los datos de transacciones bancarias, las compras en tiendas online, etc.
Datos no estructurados: son los que carecen de un formato determinado y no pueden ser almacenados en una tabla. Pueden ser de tipo texto (los que generan los usuarios de foros, redes sociales, documentos de Word, etc.), y los de tipo no-texto (cualquier fichero de imagen, audio, vídeo …). Este tipo de datos no tiene campos fijos y normalmente se tiene poco control sobre ellos. Su manipulación requiere tecnología de bases de datos bigdata, también conocidas como bases de datos NoSQL (Not only SQL).
Datos semiestructurados: poseen organización interna o marcadores que facilitan el tratamiento de sus elementos. No pertenecen a bases de datos relacionales. Es el caso de documentos XML, HTML o los datos almacenados en bases de datos NoSQL, que tienen una cierta estructura, aunque sin llegar a estar totalmente estructurados. También se pueden incluir en este tipo de datos los multiestructurados o híbridos (datos de mercados emergentes, e-commerce, datos meteorológicos, etc.).
6.4 ¿Por qué bases de datos NoSQL?
Lo que hace que el big data sea tan útil para muchas empresas e instituciones es el hecho de que proporciona respuestas a muchas preguntas que dichas empresas e instituciones ni siquiera sabían que tenían. En otras palabras, proporciona un punto de referencia. Con una cantidad tan grande de información, los datos pueden ser moldeados o probados de cualquier manera que la organización considere adecuada. Al hacerlo, las organizaciones son capaces de identificar los problemas de una forma más comprensible.
La recopilación de grandes cantidades de datos y la búsqueda de tendencias en ellos permite que las organizaciones sean más ágiles y actúen mucho más rápidamente, sin problemas y de manera más eficaz. También les permite eliminar las áreas problemáticas antes de que los problemas acaben con sus beneficios o su reputación.
El análisis de big data ayuda a las organizaciones a aprovechar sus datos y utilizarlos para identificar nuevas oportunidades. Eso, a su vez, conduce a movimientos de negocio (o de otro tipo) más inteligentes, operaciones más eficientes, mayores ganancias y clientes más satisfechos. Las organizaciones más existosas con big data consiguen valor de las siguientes formas:
- Reducción de costes. Las grandes tecnologías de datos, como Hadoop y el análisis basado en la nube, aportan importantes ventajas en términos de costes cuando se trata de almacenar grandes cantidades de datos, además de identificar maneras más eficientes de hacer negocios.
- Mejores decisiones y más rápidas. Con la velocidad de las bases de datos NoSQL y la analítica en memoria, combinada con la capacidad de analizar nuevas fuentes de datos, las organizaciones pueden analizar la información inmediatamente y tomar decisiones basadas en lo que han aprendido.
- Nuevos productos y servicios. Con la capacidad de medir las necesidades de los clientes y su satisfacción a través de análisis, viene la posibilidad de dar a los clientes lo que quieren. Con la analítica de big data, cada vez son más las organizaciones que están creando nuevos productos para satisfacer las necesidades de los clientes.
Existen ciertas diferencias entre las fuentes de datos tradicionales y las nuevas fuentes de datos que considera big data. Un resumen de las mismas puede verse en la Tabla 6.1.
| Tradicionales | Big data |
|---|---|
| Bases de datos relacionales | Bases de datos relacionales + NoSQL |
| Consultas | Consultas, capturas y procesamientos |
| Datos homogéneos | Datos heterogéneos |
| Ámbito de la informática | Todos los ámbitos |
En primer lugar, la tecnología tradicional de almacenamiento y gestión de datos (desde final de los años 80) han sido las bases de datos relacionales. Aunque las bases de datos relacionales no son, ni mucho menos, una tecnología en desuso, los entornos big data consideran otras tecnologías como, por ejemplo, las bases de datos NoSQL, que son bases de datos no relacionales optimizadas para modelos de datos sin esquema y de desempeño escalable. También son muy conocidas por su facilidad de desarrollo, baja latencia y resiliencia (Amazon Web Services, 2018).
A diferencia de las bases de datos basadas en SQL, las bases NoSQL no usan tablas tradicionales con líneas y columnas para almacenar datos, sino que los organizan con técnicas más flexibles, como, por ejemplo, documentos, gráficos, pares de valores y columnas. Por ello, son ideales para aplicaciones en las que se procesan grandes volúmenes de datos y que requieren estructuras flexibles. Como los sistemas NoSQL hacen uso de clústeres de hardware y servidores de nube, las capacidades se distribuyen de manera uniforme y la base de datos funciona con fluidez, aunque el volumen de datos sea grande. A diferencia de las bases de datos relacionales, cuyo rendimiento se reduce notablemente cuando aumenta el volumen de datos, las bases NoSQL suponen una solución potente, flexible y escalable incluso con grandes volúmenes de datos. Otra particularidad de los sistemas NoSQL es el escalamiento horizontal. Las bases de datos SQL relacionales cuentan con un escalamiento vertical y toda su capacidad de rendimiento se basa en un solo servidor. Sin embargo, en general, las soluciones NoSQL distribuyen los datos en varios servidores. Si aumenta el volumen de datos, simplemente se añaden nuevos servidores.52
Otra gran diferencia respecto a las tecnologías tradicionales es que los entornos big data no solo se centran en la consulta de datos, sino también en su captura y procesamiento (véase la Tabla 6.1). Además, las fuentes de datos pueden proveer datos heterogéneos con formatos heterogéneos. Estas diferencias hacen que no siempre sea suficiente un ámbito de trabajo puramente informático, tendiendo a equipos multidisciplinares cuando se habla de proyectos big data (ingeniería, estadística, etc.).
6.5 Bases de datos NoSQL
6.5.1 Fundamentos de las bases de datos NoSQL
El término NoSQL se usa la primera vez en 1998 para referirse a una base de datos relacional sin SQL (Strozzi, 1998). NoSQL no significa estar en contra de SQL, y de hecho esto suele ser una falacia encontrada en la literatura. Sin embargo, para determinados problemas hay otras soluciones de almacenamiento más apropiadas. En la actualidad el término NoSQL se refiere a bases de datos que no solo tienen SQL (not only SQL).
Hay una gran variedad de sistemas de gestión de bases de datos que no usan SQL como principal lenguaje de consultas. Los datos almacenados no requieren estructuras fijas como tablas y no se garantizan completamente los principios ACID (atomicity, consistency, isolation, durability) que sí deben cumplir las bases de datos relacionales (SQL):
- Atomicidad. Las transacciones se ejecutan completamente o no. Si fallan es como si ni siquiera se hubieran intentado ejecutar.
- Consistencia. Un sistema consistente garantiza que cualquier transacción llevará a la base de datos de un estado válido a otro estado válido. Cualquier dato que se escriba en la base de datos tiene que ser válido de acuerdo con todas las reglas de integridad definidas en el modelo.
- Aislamiento. Cuando varias transacciones se ejecutan en paralelo, cada una de ellas ataca la base de datos de la misma manera a como lo haría si se ejecutara cada operación individual de forma aislada o secuencial.
- Durabilidad. El resultado de las transacciones es un cambio en el estado del sistema persistente. Si se apaga la máquina y se arranca de nuevo, el cambio producido por la transacción aún está presente.
Nota
Una transacción en una base de datos se refiere a un bloque de operaciones sobre los datos que debe completarse en su conjunto, o de lo contrario, en caso de un error puntual, se restaura el estado de la base de datos a su estado anterior, antes del inicio de la transacción.
A pesar de todo, las bases de datos NoSQL se denominan “no solo SQL” para subrayar el hecho de que también pueden soportar lenguajes de consulta de tipo SQL.
Se puede decir el término NoSQL aparece con la llegada de la web 2.0, ya que hasta ese momento solo subían contenido a la red aquellas empresas que tenían un portal. Pero con la llegada de aplicaciones como Facebook, Twitter o YouTube, entre otras, cualquier usuario podía subir contenido, provocando así un crecimiento exponencial de los datos (acens.com, 2014).
Es en este momento cuando empiezan a aparecer los primeros problemas relacionados con la gestión de toda esa información almacenada en bases de datos relacionales.53 En un principio, para solucionar estos problemas de accesibilidad, las empresas optaron por utilizar un mayor número de máquinas, pero pronto se dieron cuenta de que esto no solucionaba el problema, además de ser una solución muy cara. La otra opción era la creación de sistemas pensados para un uso específico que con el paso del tiempo han dado lugar a soluciones robustas, apareciendo así el movimiento NoSQL (acens.com, 2014).
Por tanto, siguiendo de nuevo a acens.com (2014), hablar de bases de datos NoSQL es hablar de estructuras que permiten almacenar información en aquellas situaciones en las que las bases de datos relacionales generan ciertos problemas debidos, principalmente, al aumento progresivo de la capacidad de almacenamiento (escalabilidad) y rendimiento al darse cita miles de usuarios concurrentes y con millones de consultas diarias.
Además, como se esbozó al principio de la sección, las bases de datos NoSQL son sistemas de almacenamiento de información que no cumplen con el esquema “entidad–relación”. Tampoco utilizan una estructura de datos en forma de tabla donde se van almacenando los datos, sino que para el almacenamiento hacen uso de otros formatos como “clave–valor”, mapeo de columnas o grafos.
Las bases de datos relacionales modernas normalmente han mostrado poca eficiencia en determinadas aplicaciones que usan los datos de forma intensiva, incluyendo el indexado de un gran número de documentos, la presentación de páginas en sitios que tienen gran tráfico y en sitios de streaming audiovisual. Las implementaciones típicas de los sistemas gestores de bases de datos realacionales (SGBDR) se han afinado, bien para una cantidad pequeña pero frecuente de lecturas y escrituras, bien para un gran conjunto de transacciones que tiene pocos accesos de escritura. Sin embargo, NoSQL puede servir gran cantidad de carga de lecturas y escrituras.
6.5.2 Necesidades no cubiertas por las bases de datos relacionales
Las bases de datos NoSQL son, principalmente, bases de datos distribuidas escalables horizontalmente y que no se basan en esquemas de datos predefinidos, por lo que ofrecen una fácil replicación y un conjunto sencillo de operaciones y consultas para el acceso a un gran volumen de datos.
La necesidad de este tipo de bases de datos surge porque hay fuentes de datos que son difíciles de modelar en bases de datos relacionales. Algunos ejemplos son texto (datos no estructurados), procesado en streaming (flujo continuo de datos) y bases de datos científicas (estructuras multidimensionales).
Como se avanzó en la Sec. 6.5.1, las características de las nuevas aplicaciones de Internet, como las redes sociales, juegos online, etc., hacen que las bases de datos NoSQL sean necesarias para conseguir mayor velocidad, escalabilidad, independencia de la localización, disponibilidad y mejor gestión, sea cual sea el tipo de datos:
- Velocidad. Para demostrar la importancia de la velocidad en Internet, sirva como ejemplo cómo dos grandes compañías monetizan la velocidad de acceso. Por un lado, Amazon tiene estudiado que cuando el tiempo de respuesta disminuye 100 ms los ingresos aumentan en un 1%. Por otro lado, Yahoo asegura que el tráfico aumenta en un 9% cuando el rendimiento mejora en 400 ms. De ahí la importancia de esta V del big data para la evolución hacia bases de datos NoSQL.
- Escalabilidad. Al principio, la web se consideró una interfaz más, pero no es solo eso; se ha convertido en un elemento generador y consumidor de datos (fundamentalmente semiestructurados y no estructurados). En el contexto actual, las compañías necesitan mantener una respuesta rápida, aunque se incremente el número de usuarios simultáneos o el volumen de datos manejado. Además, la arquitectura de las bases de datos NoSQL permite: \((i)\) escalar sin disminuir el rendimiento; \((ii)\) añadir nodos sobre la marcha, es decir, sin interrupciones del servicio; \((iii)\) evitar que se generen cuellos de botella. La Fig. 6.1 (adaptada de Lo, 2017) muestra una representación comparativa de la escalabilidad de las bases de datos NoSQL frente a las relacionales. Como se observa, aunque las bases de datos relacionales tienen un mejor rendimiento para volúmenes de datos reducidos, este se reduce drásticamente para grandes volúmenes. Mientras, el rendimiento de las bases de datos NoSQL tiende a ser constante, por lo que escalan mejor para datos masivos.

Figura 6.1: Comparativa de escalabilidad entre bases de datos relacionales y NoSQL. Elaboración propia a partir de Lo (2017).
Nota
Escalabilidad es un anglicismo que describe la capacidad de un negocio o sistema para crecer en magnitud.
- Independencia de la localización. La globalización del mercado en World Wide Web (WWW) obliga a dar servicio rápido y en todas partes del mundo. Las bases de datos no relacionales son distribuidas de acuerdo con diferentes arquitecturas como “nodo principal y nodo secundario”, o bien “peer-to-peer”.
- Disponibilidad. Similar a la independencia de la localización, la disponibilidad en el mercado WWW es uno de los factores más críticos, ya que se espera una disponibilidad de servicio 24/7. Es decir, hay que pasar de una alta disponibilidad a la disponibilidad continua, cuyas características son: \((i)\) diseño que no sigue el modelo principal-secundario; \((ii)\) centro multidatos (multi-data center); \((iii)\) disponibilidad cloud; \((iv)\) copias de datos y funcionalidad en múltiples localizaciones.
- Gestión de todos los tipos de datos. Un factor clave en las bases de datos no relacionales es la necesidad de manejar tanto datos estructurados como no estructurados y semiestructurados; y todo esto sin perder el enfoque de un almacenamiento eficiente. En ese sentido, a menudo, las bases de datos NoSQL están altamente optimizadas para las operaciones de recuperar y agregar, y normalmente no ofrecen mucho más que la funcionalidad de almacenar los registros (por ejemplo, almacenamiento clave-valor). La pérdida de flexibilidad en el tiempo de ejecución, comparada con las bases de datos SQL clásicas, se ve compensada por ganancias significativas en escalabilidad y rendimiento cuando se trata con ciertos tipos de almacenamiento de datos.
6.5.3 Tipos de almacenamiento en bases de datos NoSQL
Se pueden distinguir al menos cuatro tipos de bases de datos NoSQL (Hecht & Jablonski, 2011): clave-valor, documental, en grafo y orientadas a columnas.
Almacenamiento clave-valor. Los datos se almacenan de forma similar a los mapas o diccionarios de datos, donde se accede al dato a partir de una clave única. Los valores (datos) son aislados e independientes entre ellos, y no son interpretados por el sistema. Pueden ser variables simples, como enteros o caracteres, u objetos. Por otro lado, este sistema de almacenamiento carece de una estructura de datos clara y establecida, por lo que no requiere un formateo de los datos muy estricto. Son útiles para operaciones simples basadas en las claves. Apache Cassandra es la tecnología de almacenamiento clave-valor más reconocida por los usuarios.
Almacenamiento documental. Este tipo de base de datos almacena datos semi-estructurados. Los datos se llaman documentos, y pueden estar formateados en XML (Extensible Markup Language), JSON (JavaScript Object Notation), BSON (Binary JSON) o el que acepte la propia base de datos, pero suele ser un formato de texto. Un ejemplo de cómo se usa es un blog: se almacena el autor, la fecha, el título, el resumen y el contenido del post. Todos los documentos tienen una clave única con la que se puede acceder e identificarlos explícitamente. Estos documentos no son opacos al sistema, por lo que se pueden interpretar y lanzar consultas sobre ellos, véase la Fig. 6.2 adaptada de (Sánchez, 2017). CouchDB o MongoDB son, quizás, los sistemas de bases de datos más conocidos. Hay que hacer mención especial a MapReduce, una tecnología de Google inicialmente diseñada para su algoritmo
PageRank, que permite seleccionar un subconjunto de datos, agruparlos o reducirlos y cargarlos en otra colección, y a Hadoop, que es una tecnología de Apache diseñada para almacenar y procesar grandes cantidades de datos. Por ejemplo, MongoDB es una base de datos orientada a documentos. Los documentos se guardan en BSON, que es una forma de representar de forma binaria objetos JSON. De esta forma, con el comandoinserty pasando un objeto JSON, MongoDB crea automáticamente un documento y lo añade en la base de datos generando un ObjectId para el nuevo documento (Rubenfa, 2014). Este objeto está especialmente pensado para garantizar unicidad en entornos distribuidos como MongoDB. El campo está compuesto por 12 bytes. Los cuatro primeros bytes son un timestamp con los segundos; los tres siguientes bytes representan el identificador único de la máquina; los dos siguientes el identificador del proceso; y, para finalizar, los últimos tres bytes son un campo incremental. En definitiva, los nueve primeros bytes garantizan un identificador único por segundo, máquina y proceso. Los tres últimos bytes garantizan que cada segundo se pueden insertar 224 = 16.777.216 documentos con un identificador distinto. Esta composición del ObjectId proporciona funcionalidades muy útiles. La primera es indicar el orden de creación de los documentos. También sirve para obtener la fecha de creación del documento.

Figura 6.2: Ejemplo representativo de base de datos NoSQL documental. Elaboración propia a partir de Sánchez (2017).
Almacenamiento en grafo. Este tipo de almacenamiento maneja datos semi-estructurados y está basado en la teoría de grafos (véase Cap. 39). En las bases de datos NoSQL se establece que la información son los nodos y las relaciones entre la información son las aristas (algo similar al modelo relacional). Su mayor uso se contempla en caso de tener que relacionar grandes cantidades de datos que pueden ser muy variables. Por ejemplo, los nodos pueden contener objetos, variables y atributos diferentes en unos y otros. Las operaciones de consulta con
joinse sustituyen por recorridos a través del grafo, y se guarda una lista de adyacencias entre los nodos. A modo de ejemplo, en Facebook se considera cada usuario como un nodo, que puede tener aristas de amistad con otros usuarios, o aristas de publicación con nodos de contenidos. Soluciones como Neo4J y GraphDB son las más conocidas dentro de las bases de datos orientadas a grafos.Almacenamiento orientado a columnas. Es similar al almacenamiento documental. Su modelo de datos se define como “un mapa de datos multidimensional poco denso, distribuido y persistente” (Hecht & Jablonski, 2011). Se orienta a almacenar datos con tendencia a escalar horizontalmente, por lo que permite guardar diferentes atributos y objetos bajo una misma clave. A diferencia del documental y del clave-valor, en este caso se pueden almacenar varios atributos y objetos, pero no serán interpretables directamente por el sistema. Permite agrupar columnas en familias y guardar la información cronológicamente, mejorando el rendimiento. Esta tecnología se suele usar en casos con 100 o más atributos por clave. Su precursor es BigTable de Google, pero han aparecido nuevas soluciones como HBase o HyperTable.
6.5.4 Limitaciones de las bases de datos NoSQL
Las bases de datos NoSQL no solo tienen ventajas; también tienen algunas limitaciones, tanto técnicas como de carácter no tecnológico.
Entre las técnicas se encuentran: \((i)\) cómo se modelan los datos correctamente para maximizar las capacidades; \((ii)\) nivel bajo de seguridad; \((iii)\) no soporte de transacciones; \((iv)\) falta de madurez en Business Intelligence; y \((v)\) problemas de compatibilidad ya resueltos en los modelos relacionales. Entre las de carácter no tecnológico pueden citarse \((i)\) la falta de expertos; \((ii)\) la resistencia al cambio; \((iii)\) la disponibilidad del vendedor; y \((iv)\) que el código abierto puede implicar problema de soporte para las empresas.
6.6 Integración de bases de datos NoSQL en R
En esta sección se verá cómo R puede ser utilizado para conectarse a una base de datos NoSQL: en particular a MongoDB. En la Sec. 6.6.1 se presenta una introducción a MongoDB. En la Sec. 6.6.2 se explican los paquetes de R utilizados para acceder a MongoDB. La Sec. 6.6.3 indica cómo conectarse a una base de datos MongoDB remota. Las secciones 6.6.4 y 6.6.5 realizan consultas y análisis sobre una colección de viajes realizados por los usuarios de un servicio de bicicletas compartidas con sede en la ciudad de Nueva York.
6.6.1 Introducción a MongoDB
MongoDB (de la palabra inglesa humongous, que significa ‘enorme’) es un sistema de base de datos NoSQL orientado a documentos, desarrollado bajo el concepto de código abierto. MongoDB forma parte de la nueva familia de sistemas de bases de datos NoSQL. En lugar de guardar los datos en tablas como se hace en las bases de datos relacionales, MongoDB guarda estructuras de datos en documentos similares a JSON con un esquema dinámico (MongoDB utiliza una especificación llamada BSON), haciendo que la integración de los datos en ciertas aplicaciones sea más fácil y rápida. MongoDB soporta la búsqueda por campos, consultas de rangos y expresiones regulares. Las consultas pueden devolver un campo específico del documento, pero también puede ser una función JavaScript definida por el usuario. Cualquier campo en un documento de MongoDB puede ser indexado, al igual que es posible hacer índices secundarios. El concepto de índices en MongoDB es similar a los encontrados en bases de datos relacionales. Tecnológicamente, MongoDB es una base de datos multiplataforma, orientada a documentos, que brinda alto rendimiento, alta disponibilidad y facilita la escalabilidad.
MongoDB trabaja con el concepto de colección y documento. La Tabla 6.2 muestra la relación de esta terminología respecto a las bases de datos relacionales.
| Bases de datos relacionales | MongoDB |
|---|---|
| Bases de datos | Bases de datos |
| Tabla | Colección |
| Tupla o fila | Documento |
| Tabla Join | Documentos incrustados (embedded) |
| Primary Key | Por defecto, key_id (gestionada por MongoDB) |
Asimismo, MongoDB proporciona una función, MapReduce, que se puede utilizar para el procesamiento por lotes de datos y operaciones de agregación. El framework de agregación permite realizar operaciones similares a las que se obtienen con el comando SQL GROUP BY. El framework de agregación está construido como un pipeline (flujo de trabajo) en el que los datos van pasando a través de diferentes etapas en las cuales estos datos son modificados, agregados, filtrados y formateados hasta obtener el resultado deseado (véase ejemplo esquemático en la Fig. 6.3, adaptada de Morgan (2015)). Todo este procesado es capaz de utilizar índices, si existieran, y se produce en memoria.
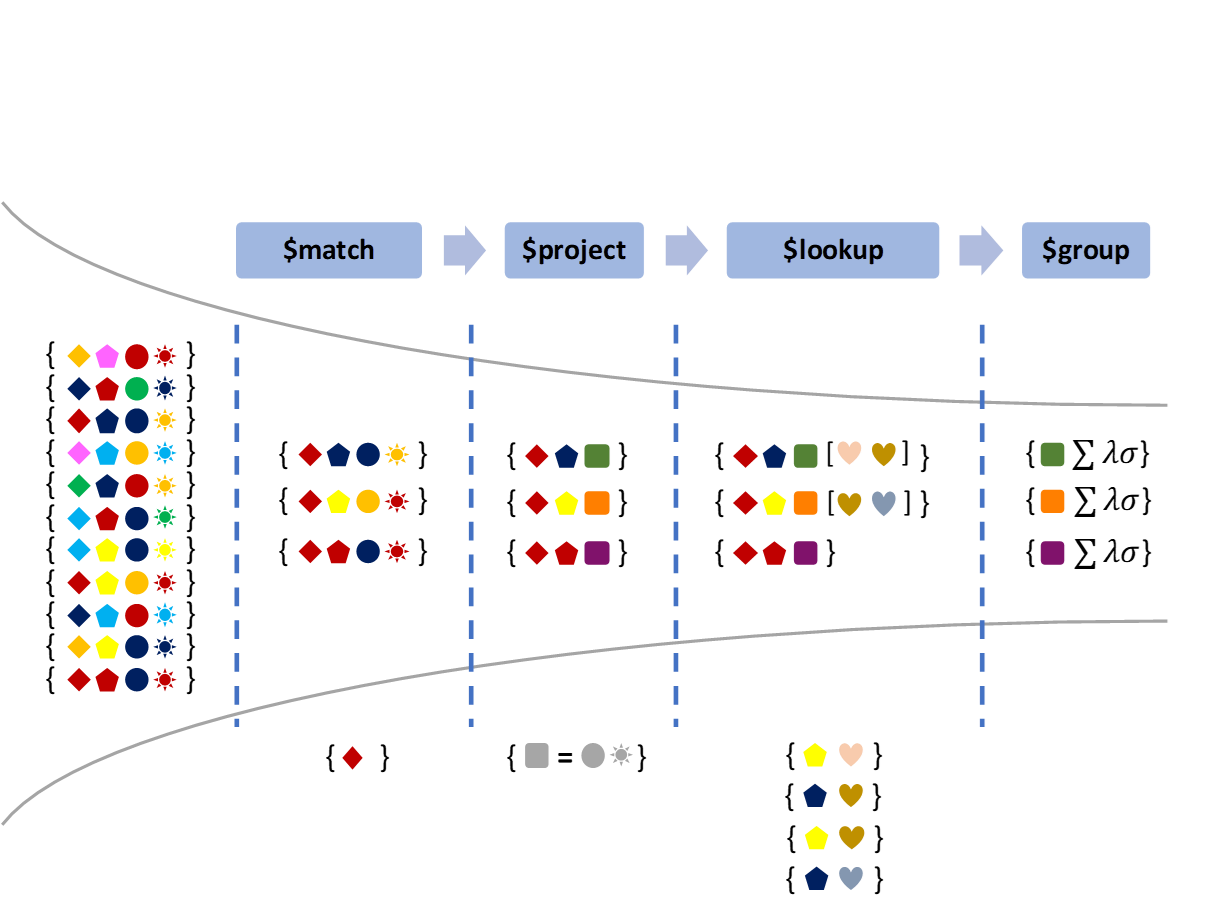
Figura 6.3: Ejemplo esquemático del \(pipeline\) de agregación en MongoDB. Elaboración propia a partir de Morgan (2015).
6.6.2 Plataforma tecnológica para el caso práctico
Para la realización del caso práctico se utiliza Atlas,54 un servicio en la nube gratuito para manejar bases de datos MongoDB. Atlas es fácil de configurar y tiene conjuntos de datos de muestra para ejemplos de R con MongoDB. Puede cargar conjuntos de datos de muestra usando el botón ... junto al de colecciones en la página de su clúster (el servidor). No obstante, aunque en Atlas se puede crear un clúster específico, en este ejemplo práctico se parte de uno ya creado.
Adicionalmente, a modo de apoyo, se recomienda utilizar una herramienta cliente para conectarse a MongoDB y poder inspeccionar los datos contenidos. Es muy útil para realizar las consultas. Puede considerarse la herramienta para la gestión de la instalación de MongoDB.55 Además, si se crea el propio clúster en Atlas, este tiene una interfaz amigable para inspeccionar los datos.
Como complemento a estas funciones, existe documentación de las colecciones de documentos y la información contenida en esta base de datos56 de ejemplo.
Para la resolución de ejercicios puede consultarse el Manual de MongoDB,57 que contiene ejemplos y explicaciones de la sintaxis de MongoDB.
6.6.2.1 Paquetes R utilizados
El controlador R preferido por la comunidad de MongoDB es mongolite; por ello se utiliza en los siguientes ejemplos. Es rápido y tiene una sintaxis similar a la del shell MongoDB. Mongolite es el controlador R para MongoDB más reciente y puede realizar operaciones de indexación, canalizaciones de agregación, cifrado TLS (transport layer security) y autenticación SASL (simple authentication and security layer), entre otras. Está basado en los paquetes jsonlite y mongo-c-driver. Se puede instalar desde CRAN o desde RStudio. Existen otros paquetes para conectar MongoDB y R, como, por ejemplo, RMongo y rmongodb, aunque no han estado muy activos en GitHub últimamente, por lo que carecen de soporte.
Para poder usar el paquete mongolite hay que instalarlo previamente, además de importar la librería con el siguiente comando.
6.6.3 Conexión y acceso a MongoDB desde R
La variable cadena_conexion representa la cadena de conexión a MongoDB en Atlas. Si se desea, se puede sustituir por otro servidor o clúster en Atlas, o por un servidor local.
cadena_conexion <- "mongodb+srv://user01:user01@cluster0.mcblc3z.mongodb.net/test"En opciones de seguridad se establece la no validación de certificados SSL (secure sockets layer), para evitar que exista un error de conexión a Atlas.
opciones_conexion <- ssl_options(weak_cert_validation = T)Nota
En entornos reales de producción se aconseja realizar esta comprobación por razones de seguridad.
Después de establecer la conexión a MongoDB se recupera la colección trips (colección de viajes de la base de datos sample_training) con la función mongo() en código R. Esta colección contiene datos de viajes realizados por los usuarios de un servicio de bicicletas compartidas con sede en la ciudad de Nueva York.
viajes <- mongo(collection = "trips", db = "sample_training", url = cadena_conexion, options = opciones_conexion)Se puede verificar que el código está conectado a la colección mediante la consulta del número total de documentos en esta colección. Para hacerlo, se usa la función count().
viajes$count()
#> [1] 100006.6.4 Obtención de datos en R desde MongoDB
Ahora que hay una conexión establecida con la base de datos, se pueden leer los datos de la misma para ser procesados por R. Para recuperar datos de MongoDB y mostrarlos se puede usar la interfaz de usuario de Atlas (en este caso para ver los documentos de trip_collection). Se puede obtener cualquier documento de muestra de la colección usando la función $iterate().$one(), pudiéndose, así, examinar la estructura de los datos de la colección.
Una vez se conoce la estructura de los documentos, se pueden realizar consultas más avanzadas, como buscar los tres viajes más largos y luego enumerar la duración en orden descendente. La consulta propuesta utiliza operadores de clasificación y límite58 para producir este conjunto de resultados.
viajes$find(sort = '{"tripduration" : -1}', limit = 3)
#> tripduration start station id start station name end station id
#> 1 326222 391 Clark St & Henry St 310
#> 2 279620 3165 Central Park West & W 72 St 3019
#> 3 173357 3155 Lexington Ave & E 63 St 3083
#> end station name bikeid usertype birth year
#> 1 State St & Smith St 18591 Subscriber 1979
#> 2 NYCBS Depot - DEL 17547 Customer
#> 3 Bushwick Ave & Powers St 15881 Customer
#> start station location.type start station location.coordinates
#> 1 Point -73.99345, 40.69760
#> 2 Point -73.97621, 40.77579
#> 3 Point -73.96649, 40.76440
#> end station location.type end station location.coordinates
#> 1 Point -73.98913, 40.68927
#> 2 Point -73.98193, 40.71663
#> 3 Point -73.94100, 40.71248
#> start time stop time
#> 1 2016-01-01 01:58:20 2016-01-04 20:35:23
#> 2 2016-01-02 17:07:26 2016-01-05 22:47:46
#> 3 2016-01-02 15:25:36 2016-01-04 15:34:536.6.5 Análisis de datos de MongoDB en R
Para analizar datos de MongoDB en R con más detalle, se puede usar el marco de agregación de datos de MongoDB. Este marco permite a los operadores crear canalizaciones de agregación que ayuden a obtener los datos con una sola consulta.
Para saber cuántos suscriptores realizaron viajes de una duración mayor que 240 segundos y regresaron a la misma estación donde comenzaron, la consulta usa la cláusula $expr, que compara dos campos en el mismo documento.
query <- viajes$find('{"usertype":"Subscriber","tripduration":{"$gt":240},
"$expr": {"$eq": ["$start station name","$end station name"]}}')Combinando estos operadores con código R, también se puede ver, por ejemplo, qué tipo de usuarios es más común: suscriptores o clientes únicos. Para ello, se pueden agrupar usuarios por el campo usertype, que define el tipo de usuario.
tipos_usuario <- viajes$aggregate('[{"$group":{"_id":"$usertype",
"Count": {"$sum":1}}}]')Para comparar los resultados, se pueden visualizar (véase Fig. 6.4). Es conveniente convertir los datos obtenidos de mongolite en un data.frame (marco de datos) y, por ejemplo, usar el paquete ggplot2, para trazar estos datos.
library("ggplot2")
df <- as.data.frame(tipos_usuario)
ggplot(df, aes(x = reorder(`_id`, Count), y = Count)) +
geom_bar(stat = "identity", color = "blue", fill = "pink") +
geom_text(aes(label = Count)) +
coord_flip() +
xlab("Tipo de usuario")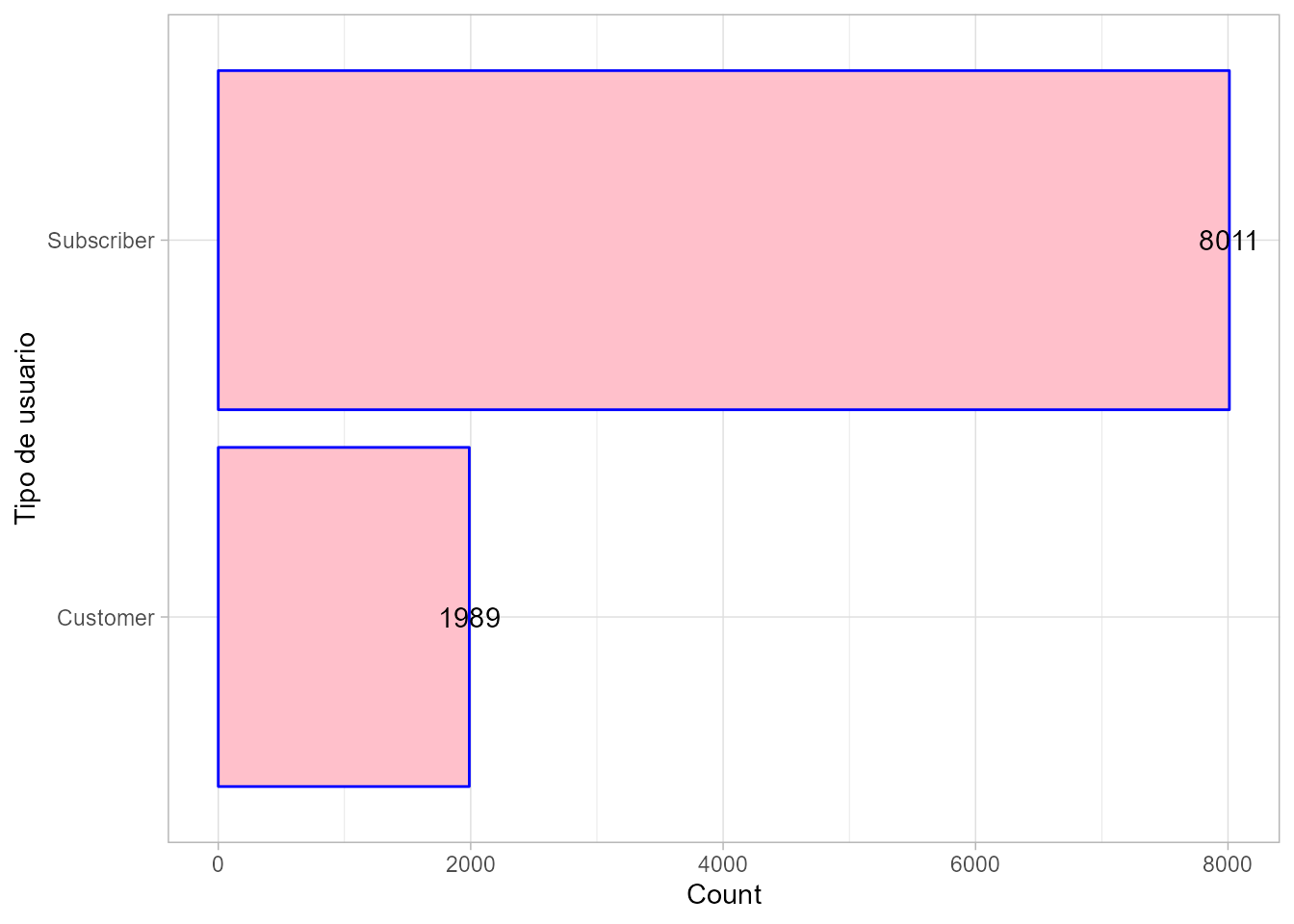
Figura 6.4: Suscripción por tipo de usuario.
Resumen
En este capítulo se presenta el concepto de big data, por qué surge y qué aporta respecto a soluciones previas.
En particular, se discute qué son las bases de datos NoSQL y cuáles son sus diferencias con las bases de datos relacionales (más tradicionales).
Posteriormente, se explican algunas limitaciones de las bases de datos NoSQL.
Finalmente, como ejemplo, se muestra la integración de datos en R desde MongoDB, explicando cómo acceder a este tipo de datos y cómo analizarlos en el caso concreto de una base de datos documental como MongoDB.