Capítulo 2 Metodología en ciencia de datos
Gema Fernández-Avilés\(^{a}\) y Ramón A. Carrasco\(^{b}\)
\(^{a}\)Universidad de Castilla-La Mancha
\(^{b}\)Universidad Complutense de Madrid
2.1 Preliminares
En el Cap. 1 se puso de manifiesto que el método científico es el elemento que define la ciencia. Bunge (2018), al hablar del método científico, lo define como: “un procedimiento para tratar un conjunto de problemas […]. Los problemas del conocimiento, a diferencia de los del lenguaje o los de la acción, requieren la invención o la aplicación de procedimientos especiales adecuados para los varios estadios del tratamiento de los problemas…”. De acuerdo con su concepción del método, Bunge (2018) destaca ocho operaciones en la aplicación de este:
Enunciar preguntas bien formuladas y verosímilmente fecundas.
Arbitrar conjeturas, fundadas y contrastables con la experiencia, para contestar las preguntas.
Derivar consecuencias lógicas de las conjeturas.
Arbitrar técnicas para someter las conjeturas a contraste.
Someter a contraste esas técnicas para comprobar su relevancia y la validez que merecen.
Llevar a cabo la contrastación e interpretar sus resultados.
Estimar la pretensión de verdad de las conjeturas y la fidelidad de las técnicas.
Determinar los dominios en los cuales valen las conjeturas y las técnicas, y formular los nuevos problemas originados por la investigación.
A su vez, sugiere una serie de reglas para la ejecución ordenada de las operaciones anteriores:
Formular el problema con precisión y, al principio, específicamente.
Proponer conjeturas bien definidas y fundadas de algún modo, y no suposiciones que no comprometan cuestiones concretas ni tampoco ocurrencias sin fundamento visible.
Someter las hipótesis a contrastación dura, no laxa.
No declarar verdadera una hipótesis satisfactoriamente confirmada; considerarla, en el mejor de los casos, como parcialmente verdadera.
Preguntarse por qué la respuesta es como es y no de otra manera.
Sin embargo, de acuerdo con Montero (1997), estas reglas no son definitivas ni infalibles y necesitan de ulterior perfeccionamiento, que se llevará a cabo a lo largo de la investigación científica. Además, las reglas del método científico no son autosuficientes, necesitan apoyarse en la inteligencia y creatividad humanas.
En resumen, es el tratamiento sistemático de los problemas, de la forma descrita, y no la certeza de los resultados obtenidos o la utilización de las técnicas muy concretas y específicas, el que garantiza el carácter científico de las conclusiones (Cancelo, 1997). La ciencia de datos, como no podía ser de otra forma, proporciona una serie de metodologías que guían el trabajo de los científicos de datos. Las principales metodologías se presentan a continuación.
2.2 Principales metodologías en ciencia de datos
En un proyecto de ciencia de datos es muy importante la metodología, pues proporciona al científico de datos una estrategia y un marco con el que trabajar. Desde finales del siglo XX se han ido proponiendo diversas metodologías, centradas en la resolución de problemas concretos mediante el uso de los datos, que hoy podrían englobarse bajo el paraguas común de la ciencia de datos.
Estas metodologías han nacido y se han desarrollado en el ámbito de los problemas de negocio, aunque todas son extrapolables a otros ámbitos de conocimiento (educación, ciencia, salud, etc.). Por tanto, en este capítulo (y, en general, en todo el manual) el término de “negocio” (empleado en las propias metodologías frecuentemente) debe ser entendido en sentido amplio, abarcando los diversos ámbitos del conocimiento en los que se aplica la ciencia de datos.
Por su amplio uso, destacan tres metodologías:
Obtención de conocimiento en bases de datos (en inglés Knowledge Discovery in Databases, KDD), propuesta por Fayyad et al. (1996) e inspirada en un trabajo previo de Brachman & Anand (1994), fue la primera metodología aceptada por la comunidad científica. Se trata del primer intento serio de sistematizar el proceso conocido hoy día como ciencia de datos y en aquellos tiempos como conocimiento basado en bases de datos, pues se centraba en la minería de datos.
SEMMA, acrónimo que coincide con las etapas de las que consta (en inglés, Sample, Explore, Modify, Model and Assess) fue desarrollada y mantenida por el Instituto SAS en 2012. Se define como el proceso de selección, exploración y modelización de grandes bases de datos para descubrir patrones de negocio desconocidos.
CRISP-DM, acrónimo en inglés de Cross Industry Standard Process for Data Mining, planteada inicialmente en 1996, publicada formalmente en Chapman et al. (2000) y mantenida durante varios años por la compañía SPSS, posteriormente adquirida por IBM, que se ha encargado de mantenerla y refinarla hasta la actualidad. Esta metodología define una secuencia flexible de seis fases que permiten la construcción e implementación de un modelo de minería de datos para ser utilizado en un entorno real, que contribuya a respaldar la toma de decisiones de negocio. Se considera la metodología más utilizada en la actualidad (Azevedo & Santos, 2008; Shafique & Qaiser, 2014, entre otros) y se describe en la siguiente sección.
2.3 CRISP-DM para ciencia de datos
La metodología CRISP-DM consta de seis etapas, que no han variado desde su publicación en 2000 (Fig. 2.1) y una serie de funciones que se han sido refinando en el tiempo (CRISP-DM, 2021). De manera esquemática, dichas etapas son:
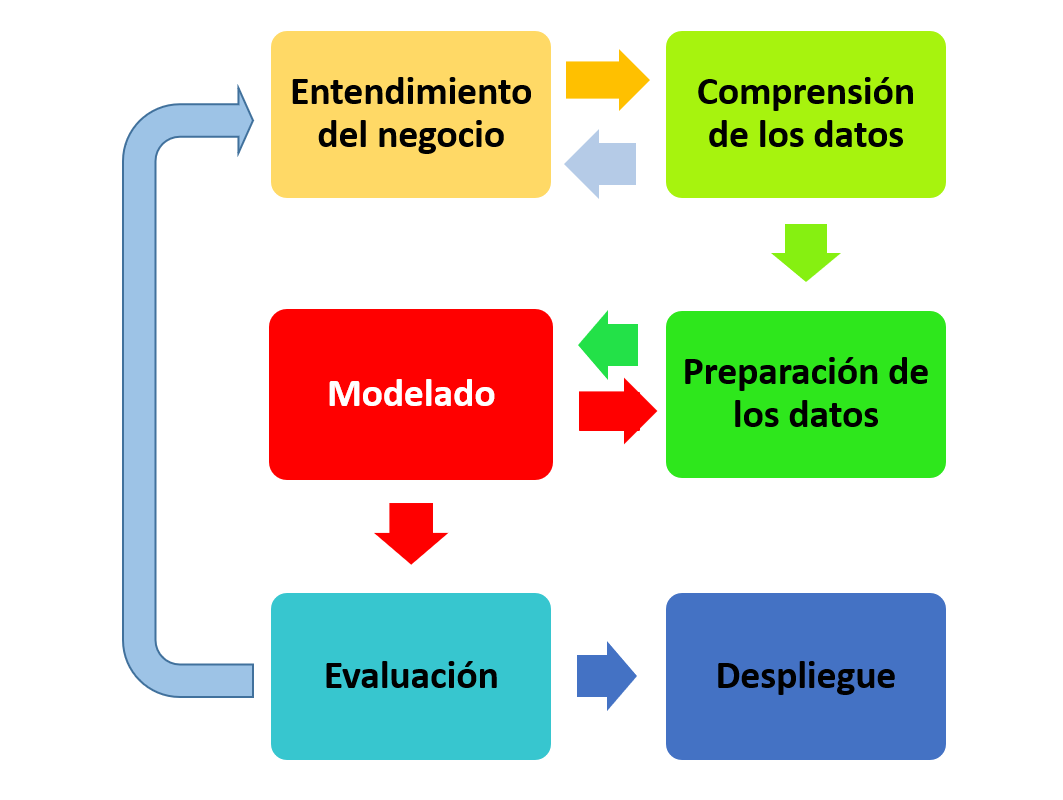
Figura 2.1: Etapas de la metodología CRISP-DM.
-
Entendimiento del negocio. Fundamental para el éxito del mismo. Consta de cuatro fases:
Determinación de los objetivos de negocio, consensuados previamente con la organización. Es importante fijar los key performance indicators (KPI) que permitan medir fidedignamente el grado de consecución de dichos objetivos.
Evaluación de la situación actual. Inventariar las fuentes de datos que estarán disponibles, los recursos materiales y humanos con los que se podrá contar, los factores de riesgo y el plan de contingencia para los mismos.
Determinación de los objetivos del proyecto, que debe alinearse con el correspondiente rendimiento de los modelos (por ejemplo, cuál debe de ser su nivel de precisión).
Plan del proyecto, con los procesos a realizar y recursos asignados.
-
Comprensión de los datos. Consta de cuatro fases que giran en torno a los datos:
Recopilación, tanto de datos internos como externos a la organización. Esta fase incluye, si es necesario, la obtención de datos adicionales y el etiquetado de casos no clasificados con anterioridad.
Descripción, especificando aspectos como la cantidad de datos disponibles, anticipando posibles problemas de rendimiento en el modelado posterior, tipología de las variables (numéricas, categóricas, booleanas, etc.), codificación de las mismas (especialmente para las categóricas), etc.
Exploración, a tavés del análisis exploratorio de datos (AED). Esta tarea ayuda a formular hipótesis sobre los datos y dirige las posteriores etapas de preparación y modelado.
Verificación de la calidad, detectando problemas como la existencia de valores perdidos, errores en datos (por ejemplo, tipográficos), errores de las mediciones (datos que son correctos pero que están expresados en unidades de medida incorrectas), incoherencias en la codificación (especialmente en las variables categóricas).
-
Preparación de los datos. Esta etapa del proyecto suele ser la que requiere más tiempo y esfuerzo (frecuentemente más del 70 %). Consta de cinco fases:
Selección: se toman decisiones sobre los casos o filas que hay que seleccionar y sobre los atributos (variables) o columnas que hay que incluir.
Limpieza: si en la subfase de verificación de la calidad de los datos se han detectado problemas, hay que subsanarlos. Los valores perdidos se pueden excluir o interpolar; los errores en los datos se pueden corregir con algún esquema lógico o manualmente; si hubiera incoherencias en la codificación se podría llevar a cabo una recodificación que sustituyese a la codificación original.
Construcción: a partir de los datos ya disponibles, de nuevos atributos (variables) o columnas y de nuevas filas o registros.
Integración: necesaria para construir un concepto de negocio unificado (por ejemplo, el concepto de cliente) si se han usado diversas fuentes (tíquet de compra y registros de cliente). La fusión de columnas con algunas claves en común (join), adición de filas con las columnas en común (union), la agrupación, etc., se utilizan frecuentemente.
Formateo: orientada a las necesidades de los modelos que se usarán posteriormente. La conversión de variables categóricas a numéricas (usando técnicas de one hot encoding) o viceversa, la normalización (usando normalizaciones min-max o z-score), etc., son tareas comunes en esta etapa.
-
Modelado: se trata de que los modelos ingieran dichos datos y aprendan de ellos, de forma automática, cómo resolver el problema de negocio planteado mediante técnicas, especialmente de machine learning. Las subfases de las que consta esta fase son:
Selección de técnicas de modelado, si se va a usar machine learning supervisado o no supervisado y, especifícamente, el tipo de algoritmos a usar en cada una de estas técnicas. Por supuesto, se tienen en cuenta los requisitos fijados en la primera fase, la cantidad y tipo de datos de los que se dispone, los requisitos concretos de cada modelo, etc.
Generación de un diseño de comprobación, a través de medidas y criterios de bondad del modelo: el área bajo la curva ROC, el criterio de información de Akaike (AIC), el coeficiente de determinación lineal (\(R^2\)), la matriz de confusión, etc.
Generación de modelos, que se entrenan oportunamente para seleccionar, posteriormente, el más adecuado.
Validación del modelo, en función de los modelos generados y del plan de pruebas especificado.
Evaluación. Se debe comprobar que el modelo final generado cumple las expectativas de negocio especificadas en la primera fase. Hay que hacer hincapié en este aspecto ya que se suele confundir en la práctica esta fase de evaluación con la subfase de la anterior etapa de validación del modelo. Ahora la evaluación se lleva a cabo desde el punto de vista del negocio. Así, por ejemplo, cabe plantearse si con el modelo elegido se pueden alcanzar las metas de negocio especificadas y medidas con los correspondientes KPI. Tras esta evaluación de los resultados del modelo se abre un proceso de revisión que permitirá valorar si cumple las expectativas o se tiene que volver a etapas anteriores.
-
Implementación. El conocimiento obtenido con el modelado es puesto en valor en esta fase de cara a satisfacer los objetivos de negocio planteados en el proyecto. Este despliegue depende mucho del tipo de proyecto que se esté realizando, aunque generalmente incluye las actividades siguientes:
Planificación del despliegue: del modelado y/o del conocimiento obtenido.
Planificación del control y del mantenimiento. Así, por ejemplo, hay que verificar que el modelo está cumpliendo con las expectativas para las que se ha desarrollado, comprobar si hay que reentrenarlo o sustituirlo por otro, etc.
Creación del informe final: para comunicar los resultados del proyecto y los pasos siguientes.
Revisión final del proyecto: donde se establecen las conclusiones finales y se formalizan las lecciones aprendidas para incorporarlas a futuros proyectos de ciencia de datos.
Para concluir, cabe subrayar que, aunque son varias las metodologías propuestas, CRISP-DM es la más completa, la más desarrollada y, además, puede ser implementada, como todas las propuestas en la literatura, mediante el lenguaje R.
Resumen
El método científico es el elemento clave en la definición de ciencia.
Bunge (2018) establece una serie de reglas y características para la correcta aplicación de la metodología científica. En un proyecto de ciencia de datos es muy importante la metodología, pues proporciona al científico de datos una estrategia y un marco en el que trabajar. Entre ellas destaca el CRISP-DM como la más aceptada y utilizada por las empresas y científicos.
El CRISP-DM se basa en la organización flexible de seis pilares: entendimiento del negocio, compresión de los datos, preparación de los datos, modelado, evaluación e implementación.