Capítulo 5 Gestión de bases de datos relacionales
Ismael Caballero\(^{a}\), Ricardo Pérez del Castillo\(^{a}\) y Fernando Gualo\(^{a,b}\)
\(^{a}\)Universidad de Castilla-La Mancha
\(^{b}\)DQTeam SL
5.1 Introducción
El mundo real en el que estamos inmersos es puramente analógico: está lleno de entidades que se relacionan entre ellas o consigo mismas a través de unos determinados eventos que representan determinados hechos. Tanto entidades como hechos tienen una colección de características observables (normalmente llamadas atributos26 en el ámbito del diseño de bases de datos), que pueden ser de interés en el contexto de una determinada aplicación.
Para estas aplicaciones que demandan el uso de datos del mundo real, es preciso realizar observaciones de esos atributos de las entidades y de los hechos que son relevantes. Al conjunto de entidades y hechos del mundo real que son relevantes para una aplicación se les conoce como Universo del Discurso (Piattini et al., 2006). Para poder tener éxito en las aplicaciones, es importante capturar la semántica del Universo del Discurso mediante los modelos correspondientes.
Los datos que son de interés para una determinada aplicación deben ser capturados mediante un proceso de observación y digitalización de los valores de los atributos relevantes de las entidades y hechos del mundo real. Durante el proceso de observación y captura se pueden producir errores que pueden derivar en problemas relacionados con la calidad de los datos (Price & Shanks, 2004). Por ejemplo, supóngase que las observaciones requieren una determinada frecuencia mínima de observación en relación con la velocidad en la producción de los hechos; si esta frecuencia no es adecuada, la cantidad de observaciones realizada será insuficiente para modelar el hecho, llevando a un estado inconsistente entre lo sucedido y lo observado.
Una vez capturados estos datos, pueden ser usados en los procesos de negocio para una tarea determinada, o bien ser analizados para producir un conocimiento del mundo real que hasta ahora no se tenía (T. Davenport & Harris, 2017).
5.2 Concepto de base de datos
Para poder habilitar el procesamiento o los análisis de forma automática mediante las potentes técnicas tratadas en el resto de capítulos de este manual, es necesario almacenar previamente los datos en algún lugar como repositorios o bases de datos, donde los datos se puedan añadir, borrar, recuperar o modificar fácilmente.
De acuerdo con Piattini et al. (2006), una base de datos (BD) es una colección o depósito de datos integrados, almacenados en soporte secundario (no volátil) y con redundancia controlada. En una base de datos, los valores correspondientes a los atributos que han de ser compartidos por diferentes usuarios y aplicaciones deben mantenerse independientes de ellos, y su definición (estructura de la base de datos), única y almacenada junto con los datos, se ha de apoyar en un modelo de datos. Este modelo debe captar las interrelaciones y restricciones existentes en las entidades y hechos del mundo real al que representan. Existen diferentes tipos de modelos que permiten estructurar y representar la semántica de los datos, como, por ejemplo, el modelo relacional (Codd, 1970), que es el fundamento de las bases de datos relacionales en las que se centra este capítulo.
En el ámbito de los Sistemas de Información, se han desarrollado programas que dan soporte a todo el proceso de creación y explotación de las bases de datos. A estos programas se los conoce como Sistemas Gestores de Bases de Datos (SGBD). Como ejemplos de estos SGBD se pueden citar Microsoft Access, Microsoft SQL Server, Oracle Server, MySQL, MariaDB, Informix, MongoDB… En cualquier caso, como se verá más adelante en este capítulo, los SGBD más utilizados son los conocidos como relacionales (SGBDR), aunque, con el auge del Big Data y del Machine Learning, esta tendencia está cambiando y empiezan a desplegarse cada vez más SGBD conocidos como not only structured query language, NoSQL (no solo lenguaje estructurado de consulta) (véase Cap. 6). Para evitar confusiones, es importante diferenciar entre la base de datos propiamente dicha (como una colección de datos almacenada en un fichero de datos) y el software SGBD específico, ya sea relacional o NoSQL: una misma base de datos, con las correspondientes adaptaciones, puede ser gestionada usando diferentes tipos de SGBD. Habitualmente, los tipos de SGBDR más usados son los que tienen capacidades multiproceso/multiusuario, ya que permiten acceder a datos compartidos mediante el uso de interfaces de datos para ejecutar diferentes tipos de análisis, empleando lenguajes de programación más potentes –o versátiles–, como R software o Python, que los lenguajes típicos de programación.
5.2.1 Gestión de los datos en una base o repositorio de datos
Las organizaciones usan datos para sus procesos de negocio. La Tabla ?? muestra la tipología de datos sugerida por Mahanti (2019).
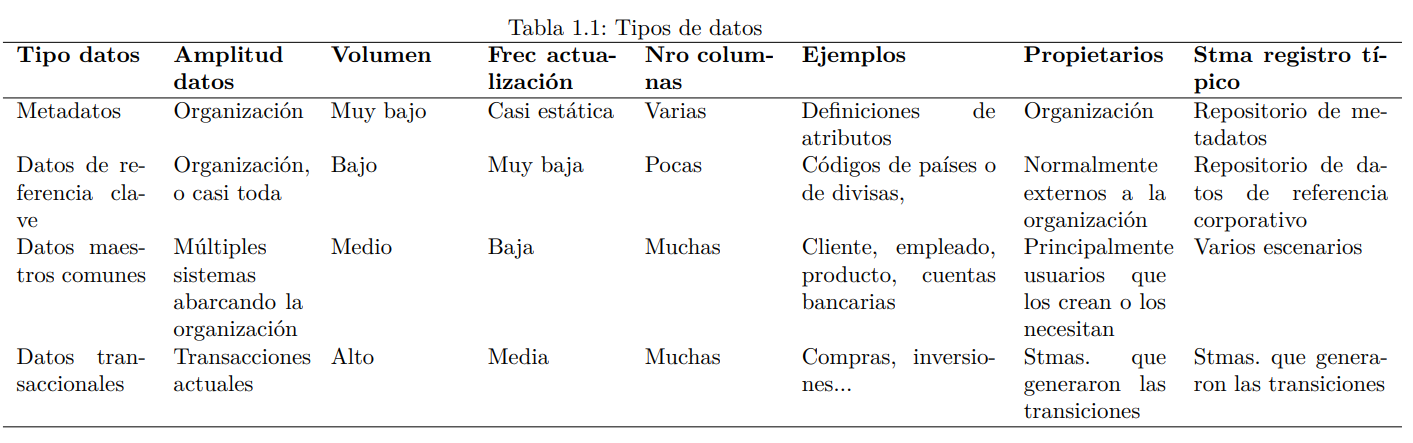
Para poder usar estos datos, las aplicaciones pueden realizar los siguientes cuatro tipo de operaciones (normalmente conocidas como “operaciones CRUD”):
- Crear datos (Create): inserta datos en el repositorio de datos.
- Leer datos (Read): recupera datos del repositorio para aprovisionar el proceso de negocio, o bien para realizar alguna operación de análisis específica.
- Actualizar datos (Update): modifica el valor de los atributos correspondientes a los hechos o entidades para actualizarlos a nuevas observaciones.
- Borrar datos (Delete): elimina en bloque o selectivamente los datos almacenados en el repositorio de los datos.
En cualquier caso, estos procedimientos de inserción, actualización, recuperación y borrado deben garantizar siempre la seguridad del conjunto de los datos, de modo que solo sean accesibles por aquellos usuarios que estén autorizados a trabajar con ellos, y siempre para el propósito establecido para los datos (Piattini et al., 2006). La forma de implementar estas operaciones depende fuertemente del formato (modelo lógico) en el que estén almacenados los datos. Aunque existen diferentes modelos (estructurados, semiestructurados, no estructurados), en este capítulo el énfasis se pone en el modelo relacional (Codd, 1970), ya que es el más ampliamente usado en el ámbito organizacional y el que implementan los SGBDR. Para poder dar soporte a las operaciones CRUD anteriormente citadas en bases de datos relacionales, se desarrolló un lenguaje llamado “lenguaje estructurado de consulta” (structured query language, SQL), que se aborda en la siguiente sección.
5.3 SQL: el lenguaje estructurado de consulta
Los principios de SQL están establecidos en el estándar internacional ISO/IEC 9075:198927 como un mecanismo para identificar y regular las expresiones necesarias que permiten manejar bases de datos relacionales. Al ser un estándar, es importante señalar que cada fabricante de SGBDR, como Oracle con Oracle Database Manager Server28 o con MySQL,29 Microsoft con SQL Server,30 IBM con DB231…, implementa en sus productos su propia versión del estándar SQL. Y aunque son prácticamente iguales, hay ligeros matices que les permiten diferenciarse de la competencia y que, por tanto, deben ser conocidos cuando se utilicen los correspondientes productos comerciales. No obstante, existen en el mercado algunas soluciones open source como MariaDB32 o PostgreSQL.33 En este capítulo, todos los ejemplos que se han desarrollado trabajan contra un servidor MySQL 8.34
SQL tiene diferentes tipos de sentencias o instrucciones que dan soporte a los diferentes aspectos de las interacciones con la base de datos. Cualquier manual de SQL permite tratar en profundidad todos los elementos sintácticos del lenguaje, pero es importante señalar que los detalles específicos de la sintaxis específica dependerán fuertemente del SGBDR empleado. Para los ejemplos propuestos en este libro, puede consultarse el manual de referencia de SQL de MySQL v8.0.35 Las siguientes secciones proporcionan una visión global de dichos grupos de sentencias.
5.3.1 SQL como lenguaje de definición de datos
Una base de datos relacional tiene una organización en forma de tabla y su concepto fundamental es el de “relación”, que no es el que el lector se puede imaginar a primera vista. Una “relación” representa un conjunto de entidades con las mismas propiedades y se compone de filas (o registros; también denominadas tuplas) cuyos valores dependen de los atributos que se representen en las columnas. Por ejemplo, una relación puede ser el conjunto de equipos de fútbol de la primera división española, siendo los atributos su presupuesto, nombre del entrenador, número de jugadores españoles…
Las bases de datos relacionales se caracterizan por utilizar el lenguaje de consulta estructurado (SQL) y, por ello, son también denominadas bases de datos SQL. En particular, SQL se utiliza para definir todos los elementos necesarios para crear y modificar las tablas de datos. Se tienen tres tipos de instrucciones básicas para gestionar las tablas como estructuras de datos:
-
Create: permite crear un componente de la base de datos, tal como la base de datos propiamente dicha, una tabla, una vista… En el siguiente ejemplo, se crea, usando instrucciones SQL, primero una base de datos llamada
Biblioteca, y luego una tablaAutorcon seis atributos (CodAtutor,Nombre,Apellido1,Apellido2,PseudonimoyNacionalidad), donde se podrán almacenar los valores correspondientes a dichos atributos, conformando así la base de datos:
create database Biblioteca
create Table Autor (
CodAutor nvarchar (20) primary key,
Nombre nvarchar(40) not null,
Apellido1 nvarchar(50) not null,
Apellido2 nvarchar(50),
Pseudonimo nvarchar(50),
Nacionalidad nvarchar (50)
);-
Alter: permite modificar la estructura de un componente, añadiendo, por ejemplo, atributos a una tabla, restricciones a un atributo o modificando el tipo de datos de algún atributo existente; también permite eliminar un atributo de una tabla existente. Siguiendo el ejemplo anterior, con la siguiente instrucción se añade un nuevo atributo,
LocalidadNacimiento, a la tablaAutor:
-
Drop: sirve para eliminar un componente específico, como una tabla, una vista… pero no sirve para eliminar los valores almacenados en una tabla. En el siguiente ejemplo, se eliminan las tablas
Escribe,AutoryLibro:
5.3.2 SQL como lenguaje de manipulación de datos
En esta sección se describen las instrucciones más importantes de SQL para el soporte a las operaciones CRUD anteriormente introducidas. Existen, por tanto, cuatro tipos de sentencia para manipular los datos:
-
Create: implementada mediante la instrucción
insert, sirve para insertar registros (también llamados tuplas) en una base de datos. En los ejemplos siguientes se insertan diversas tuplas en varias tablas, siguiendo el mismo orden en el que se especificaron los atributos cuando se creó la tabla. Así, por ejemplo, se crean los códigos “dbrown” (como valor para el atributoCodAutor) para “Dan Brown” y “cdv” (como valor para el atributoCodLibro) para su libro “El Código da Vinci”. El siguiente código SQL muestra las instrucciones necesarias:
insert into Autor values ('dbrown', 'Dan', 'Brown', '', '', 'EstadoUnidense');
insert into Libro values ('cdv', 'El Código da Vinci', 'Random House', '2003-04-23');
insert into Escribe values ('dbrown', 'cdv');-
Read: implementada mediante la instrucción
select, permite hacer consultas a la base de datos. En los siguientes ejemplos se escribe el código que selecciona \((i)\) el nombre y primer apellido de los autores con nacionalidad española, ordenados por orden alfabético delApellido1y \((ii)\) la lista todos los libros que haya escrito el autor “Pérez Reverte” (cuyoCodAutores “perezreverte”).
Select Nombre, Apellido1 from Autor where Nacionalidad like 'Español' order by Apellido1;
Select Libro.Título from Autor, Escribe, Libro where ( Libro.CodLibro = Escribe.CodLibro and Autor.CodAutor = Escribe.CodAutor) and (Escribe.CodAutor ='perezreverte');-
Update: permite actualizar los valores de las tuplas seleccionadas. En el siguiente ejemplo, se actualiza el valor del atributo
pseudonimoal valor “El Manco de Lepanto” para el autor “Miguel de Cervantes”, conCodAutor“mcervantes”:
-
Delete: su principal objetivo es eliminar, en bloque o de forma selectiva, una o varias tuplas o registros de datos que cumplan una determinada condición. En el siguiente código SQL se borra(n) la(s) tupla(s) que contiene(n) datos del autor cuyo
CodAutores “perezreverte”.
5.3.3 SQL como lenguaje de administración de datos
SQL también puede usarse para administrar los usuarios de una base de datos. Esto implica crear usuarios de la base de datos y asignarles diferentes tipos de permisos para realizar los diferentes tipos de operaciones vistos anteriormente sobre los distintos componentes de datos. Por ejemplo, para crear un usuario llamado Ismael.Caballero que tenga por contraseña LibroMDSR se puede usar la siguiente instrucción:
y la siguiente instrucción se usa para asignar al usuario Ismael.Caballero los permisos necesarios para el acceso, lectura, selección, inserción, actualización y borrado de los valores de la base de datos Biblioteca, así como para poder modificar la estructura de los componentes de la base de datos Biblioteca creada anteriormente:
GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, ALTER ON biblioteca.* TO 'Ismael.Caballero'@'%';
FLUSH PRIVILEGES;Recuérdese que los ejemplos mostrados han sido realizados para MySQL 8, aunque la sintaxis no debería ser muy diferente para otros SGBDR.
5.4 Acceso y explotación de bases de datos desde R
Como el propósito de este manual es aprender los fundamentos de la ciencia de datos usando R, en las siguientes secciones se explicará cómo implementar las operaciones CRUD usando sentencias de paquetes específicos de R. Dado que en este capítulo se usa MySQL, se utiliza el driver específico de RMySQL (Ooms et al., 2022). En caso de que se hubiese usado otro sistema gestor de bases de datos, se habría tenido que recurrir al paquete específico que contuviera el driver correspondiente. En las siguientes secciones se explica cómo conectarse a una base de datos usando las funciones correspondientes y cómo se implementan las operaciones CRUD con funciones del paquete RMySQL.
5.4.1 Conexión a una base de datos
Antes de poder realizar ninguna operación con las bases de datos gestionadas por MySQL es preciso tener instalado el paquete RMySQL y cargar los paquetes necesarios:
install.packages("RMySQL")
library("RMySQL")
library(DBI)Es necesaria también la librería DBI (R Special Interest Group on Databases (R-SIG-DB) et al., 2022) porque proporciona la infraestructura común para todos los drivers de acceso a base de datos. Además del mencionado RMySQL, otros ejemplos de drivers son RPostgres (Wickham et al., 2023), RMariaDB (Müller, Ooms, et al., 2022), odbc (Hester & Wickham, 2023) o RSQLite(Müller, Wickham, et al., 2022), por citar algunos.
Para desarrollar las explicaciones, se usa una base de datos llamada classicmodels, implementada en MySQL v8.0 y desplegada en un servidor con dirección IP 172.20.48.118 que está escuchando en el puerto 3306. El usuario que se conecta a la base de datos es Ismael.Caballero, siendo su contraseña MdsR.2022. Otros usuarios tendrían que modificar los parámetros correspondientes para realizar las conexiones a sus propias bases de datos. Se almacenan todos estos datos en variables para hacer más sencillo el mantenimiento de los scripts. Con dbConnect() se realiza la conexión. Con summary() o con dbGetInfo() se pueden mostrar los resultados de la conexión en caso de que esta se haya realizado con éxito.
Una vez terminadas todas las tareas con la base de datos, debería desconectarse mediante la instrucción dbDisconnect().
usuario = 'Ismael.Caballero'
passwd = 'MdsR.2022#'
nombrebd = 'classicmodels'
servidor = '172.20.48.118'
puerto = 3306
mibbdd = dbConnect(MySQL(), user=usuario, password=passwd, dbname=nombrebd,
host=servidor, port= puerto)
summary (mibbdd)
dbGetInfo(mibbdd)
dbDisconnect (mibdd)5.4.2 Operaciones de lectura / consulta/ selección (read) de datos
Entre las operaciones más frecuentes en cualquier tipo de bases de datos están las de lectura o consulta (read), implementadas en SQL con las sentencias de tipo select. El driver RMySQL ofrece distintas alternativas para realizar consultas de selección en R. La elección de la mejor operación dependerá de la complejidad de las consultas que se quieran realizar. Se listan a continuación:
-
dbReadTable(), que permite leer una tabla entera de una base de datos MySQL. Es recomendable usar este método si la tabla no es excesivamente grande. Se pueden almacenar los resultados en undata.framepara hacer operaciones con ellos después. La ventaja es que, sabiendo manejardata.framesen R, no se necesita aprender mucho más detalle del lenguaje SQL36 como lenguaje de manipulación de datos (LMD); sin embargo, la desventaja es que se acaba perdiendo parte del potencial expresivo de SQL para hacer algunas operaciones más fáciles y eficientes. En el siguiente ejemplo se muestra cómo cargar toda la tablacustomersen undata.framellamadotblCustomers, obteniéndose los resultados con la instrucciónsummary():
tblCustomers <- dbReadTable(mibbdd, "customers")
summary (tblCustomers)-
dbGetQuery(), que tiene más flexibilidad quedbReadTable()porque permite, mediante una sentencia SQLselect(véase más información en el tutorial de SQL en W3C37 o en la página oficial de “select” sobre MySQL,38) particularizar la consulta a la base de datos. Esto puede implicar la selección de atributos específicos o incluso el uso de filtros sobre los atributos seleccionados. Por ejemplo, si se quisieran recuperar el número y el nombre de los clientes de Madrid, se podría personalizar la consulta añadiendo las condiciones correspondientes en la cláusulawhere,39 como se muestra en siguiente código. Por comodidad, se escribe aparte la consulta SQL, en una variable, para poder manejar más fácilmente la operativa en R. Escribir esta consulta puede ser lo que entrañe más dificultad. A continuación, se ejecuta la consulta condbGetQuery()y se almacenan los resultados en undata.framepara su uso posterior. Nuevamente, se comprueba el resultado con la instrucciónsummary().
SentenciaSQL_Nombres_Clientes ="Select CustomerNumber, CustomerName from customers where city = 'Madrid'"
Consulta_Clientes_Madrid = dbGetQuery (mibbdd, SentenciaSQL_Nombres_Clientes)
summary (Consulta_Clientes_Madrid)Teniendo los resultados en data.frames, ya es posible procesarlos en R como si fuesen cualquier otro tipo de datos.
Obsérvese que las instrucciones siguientes serían equivalentes:
dbReadTable(mibbdd,"customers")
dbGetQuery (mibbdd, "select * from customers")-
dbSendQuery()combinado condbFetch(). La principal diferencia entredbSendQuery()ydbGetQuery()es que la primera no recupera datos de la base de datos y hay que traerlos explícitamente con la funcióndbFetch(). En el siguiente fragmento de código se muestra la utilización de ambas funciones con un resultado exactamente igual que en el apartado anterior.
SentenciaSQL_Nombres_Clientes ="Select CustomerNumber, CustomerName from customers where city = 'Madrid'"
Consulta <- dbSendQuery(mibbdd, SentenciaSQL_Nombres_Clientes);
dbGetInfo(Consulta)
#> $statement
#> [1] "Select CustomerNumber, CustomerName from customers where city = 'Madrid'"
#>
#> $isSelect
#> [1] 1
#>
#> $rowsAffected
#> [1] -1
#>
#> $rowCount
#> [1] 0
#>
#> $completed
#> [1] 0
#>
#> $fieldDescription
#> $fieldDescription[[1]]
#> NULL
print(paste("Consulta realizada:", dbGetStatement(Consulta)) )
Consulta_Clientes_Madrid_condbSendQuery <- dbFetch(Consulta, n=-1)
print( paste("Número de elementos devueltos en la consulta",dbGetRowCount(Consulta)))
summary (Consulta_Clientes_Madrid_condbSendQuery)En cualquier caso, para considerar la opción más adecuada deben tenerse en cuenta los siguientes aspectos:
La información de la consulta generada con
dbSendQuery()puede mostrarse con la funcióndbGetInfo().Es posible recordar la consulta SQL que se utilizó en
dbSendQuery()mediante la funcióndbGetStatement().La función
dbFetch()tiene dos argumentos: la consulta y el número de registros a recuperar; si se quieren recuperar todos los registros que haya podido producir la consulta, debe pasarse el argumenton=-1.Si se quiere saber el número de elementos que se han traído con la función
dbFetch()se puede usar la funcióndbGetRowCount().
La principal ventaja de dbSendQuery() combinado con dbFetch() es que el filtro se hace en el sistema gestor de bases de datos y solo llegan a la memoria de R los datos que se van a utilizar, que es mejor que descargar toda la tabla a la memoria de R y, después, hacer el filtro.
Para extraer información de los resultados de la consulta, se puede usar la función dbColumnInfo():
dbColumnInfo(Consulta)
#> name Sclass type length
#> 1 CustomerNumber integer INTEGER 11
#> 2 CustomerName character VAR_STRING 200El driver RMySQL no proporciona funciones para conocer directamente el tipo y tamaño de los atributos de una tabla. Mediante la función dbSendQuery() y dbColumnInfo() se puede obtener esta información haciendo una consulta que incluya los atributos en los cuales se está interesado. Por ejemplo, para conocer el tipo de datos y tamaño de los atributos de la tabla Employees se podría usar el siguiente fragmento de código:
SentenciaSQL_Tabla_Employees = "Select * from employees"
Consulta_Employees <- dbSendQuery(mibbdd,SentenciaSQL_Tabla_Employees)
dbColumnInfo(Consulta_Employees)
#> name Sclass type length
#> 1 employeeNumber integer INTEGER 11
#> 2 lastName character VAR_STRING 200
#> 3 firstName character VAR_STRING 200
#> 4 extension character VAR_STRING 40
#> 5 email character VAR_STRING 400
#> 6 officeCode character VAR_STRING 40
#> 7 reportsTo integer INTEGER 11
#> 8 jobTitle character VAR_STRING 200
dbClearResult(Consulta_Employees)
#> [1] TRUECon dbColumnInfo() se muestran los metadatos de implementación (operativos) de los atributos de la tabla Employees. Finalmente, con la instrucción dbClearResult(ConsultaEmployees) se pueden limpiar los resultados de la consulta para optimizar el sistema.
5.4.3 Operaciones de inserción (create) y actualización (update) de datos
Antes de almacenar los datos en la base de datos, es necesario crear las estructuras necesarias, que, como se avanzó anteriormente, son las tablas y los atributos. Para ello se utilizan instrucciones especiales SQL como lenguaje de definición de datos (LDD); esto incluye instrucciones para crear tablas (create table),40 para modificarlas (alter table)41 o para borrarlas (drop table).42
Para poder hacer operaciones con los datos, es preciso crear usuarios y asignarles los privilegios adecuados sobre las tablas y atributos. Ello también requiere las instrucciones especiales SQL como lenguaje de administración de datos (LAD), que incluye instrucciones para crear usuarios (create user),43 modificar ciertos aspectos de los mismos (alter user)44 y borrarlos (drop user).45
Un usuario de la base de datos que tenga privilegios suficientes sobre las estructuras creadas puede crear (insert)46 o modificar (update)47 registros de datos usando las instrucciones específicas de SQL como lenguaje de manipulación de datos (LMD) (véase cómo otorgar privilegios a un usuario para crear tablas).48
No obstante, y dado que el software en el que se centra este manual es en R, se deja fuera del alcance de este capítulo el uso de los aspectos LDD, LMD y LAD de SQL, y se cubrirán mediante la instrucciones dbWriteTable() de RMySQL los aspectos de inserción y de actualización de los registros. dbWriteTable() se usa, por tanto, para exportar datos de R a una base de datos MySQL, y puede ser usado para las acciones que se exponen a continuación, siempre y cuando el usuario que ejecute las acciones tenga suficientes permisos en el sistema gestor de bases de datos para realizarlas.
5.4.3.1 Crear una nueva tabla con datos
La creación de una nueva tabla de datos se lleva a cabo a partir de un data.frame que se puebla con datos iniciales y que tendrá tantas columnas como atributos tenga la tabla. Por ejemplo, a continuación se crea un data.frame llamado dfDatos_Prueba con dos columnas, una de tipo numérico llamada CodPrueba y otra de tipo texto llamada DatosPrueba. En este ejemplo, y a modo ilustrativo, los datos son completamente arbitrarios. Después, se construye el data.frame dfDatos_Pruebas y mediante dbListTables() se comprueba que la tabla no existe en la conexión a la base de datos. Finalmente, con dbWriteTable(), se crea la nueva tabla. Es importante tener en cuenta las posibles conexiones simultáneas a la base de datos porque se podrían generar problemas. Con dbWriteTable() se puede comprobar si la tabla se ha creado correctamente.
CodPrueba <- c(1:26)
Nombre_Prueba <- c(letters[1:26])
dfDatos_Prueba <- data.frame(CodPrueba, Nombre_Prueba)
dbListTables(mibbdd)
#> [1] "Autor" "DatosPrueba_16" "DatosPrueba_22" "Datos_Prueba_01",
#> [5] "Make" "Pelicula" "customers" "employees",
#> [9] "offices" "orderdetails" "orders""payments",
#> [13] "productlines" "products"
dbWriteTable(mibbdd, "DatosPrueba", dfDatos_Prueba, overwrite = TRUE, row.names =FALSE )
#> [1] TRUE
#>
dbListTables(mibbdd)
#> [1] "Autor" "DatosPrueba" "DatosPrueba_16" "DatosPrueba_22",
#> [5] "Datos_Prueba_01" "Make" "Pelicula" "customers" ,
#> [9] "employees" "offices" "orderdetails","orders" ,
#> [13] "payments" "productlines" "products"Es interesante pensar en la utilidad de este método para duplicar tablas en caso necesario.
5.4.3.2 Sobreescribir una tabla existente con datos actualizados
Cuando se trata de actualizar algunos valores de los atributos de la tabla o de añadir nuevos registros a la tabla, la operación es básicamente la misma que antes, pero primeramente habrá que leer la tabla y convertirla en un data.frame para actualizar en él los valores o añadir los nuevos valores (en este caso se añade una nueva fila); una vez hecho esto, se vuelve a utilizar el comando dbWriteTable() añadiendo los parámetros overwrite = TRUE (para sobrescribir toda la tabla) y row.names = FALSE. En el siguiente ejemplo se actualizan los valores de una tupla específica.
dfDatos_Prueba <- dbReadTable(mibbdd, "DatosPrueba")
dfDatos_Prueba$NombrePrueba[25] <- "en un lugar de la mancha"
dbWriteTable(mibbdd, "DatosPrueba", dfDatos_Prueba, overwrite = TRUE,
row.names =FALSE )
#> [1] TRUE
dfDatos_Prueba_Modificado <- dbReadTable(mibbdd, "DatosPrueba")5.4.3.3 Añadir nuevos registros a una tabla
Existen dos estrategias para añadir registros a una tabla. La primera es utilizar la técnica de sobreescritura descrita anteriormente. Para ello, se procede como antes: se carga la tabla en un
data.frame (en este caso dfDatos_Prueba), se añaden nuevas filas (registros) al data.frame (cargadas previamente en el data.frame dfNuevoRegistro) usando rbind(), y a continuación se sobreescribe la tabla usando dbWriteTable(). En el siguiente fragmento de código se muestra cómo añadir nuevos registros a una tabla sobreescribiéndola completamente.
dfDatos_Prueba <- dbReadTable(mibbdd, "DatosPrueba")
dfNuevo_Registro <- as.list(dfDatos_Prueba)
dfNuevo_Registro$CodPrueba <- c(27)
dfNuevo_Registro$NombrePrueba <- c("Un Valor Nuevo")
dfDatos_Prueba <- rbind (dfDatos_Prueba, dfNuevo_Registro)
dbWriteTable(mibbdd, "DatosPrueba", dfDatos_Prueba, overwrite = TRUE, row.names =FALSE)
#> [1] TRUELa opción anterior puede ser interesante si la tabla no tiene muchos registros y el coste computacional no es muy grande. Pero si se tienen muchos registros es preferible usar otra estrategia para añadir un nuevo registro a la tabla. En este caso, se puede hacer creando un data.frame compatible con la estructura de la tabla, y ejecutar la instrucción dbWriteTable() poniendo el parámetro append = TRUE. Esto añadirá el nuevo registro al final de la tabla. El siguiente fragmento de código muestra cómo realizar esta operación.
dfDatos_Prueba_Nuevos <- as.list(dfDatos_Prueba)
dfDatos_Prueba_Nuevos$CodPrueba <- 28
dfDatos_Prueba_Nuevos$NombrePrueba <- "Otro valor nuevo"
dfDatos_Prueba_Nuevos <- data.frame (dfDatos_Prueba_Nuevos)
dbWriteTable(mibbdd, "DatosPrueba", dfDatos_Prueba_Nuevos, append = TRUE, row.names =FALSE)
#> [1] TRUE
5.4.3.4 Inserción con consulta SQL usando la instrucción dbSendQuery()
Una última forma de insertar valores en una tabla es mediante la instrucción dbSendQuery, utilizando una consulta de inserción insert. En el siguiente ejemplo se muestra cómo insertar tuplas o registros mediante dbSendQuery(); en este caso, se añaden datos completamente arbitrarios a modo de ejemplo.
SentenciaSQL_Insercion ="insert into DatosPrueba value (29, 'Una tercera forma')"
dbSendQuery (mibbdd, SentenciaSQL_Insercion)
#> <MySQLResult:-365007472,0,23>5.4.4 Operaciones de borrado de datos (delete)
Finalmente, se describen las operaciones de borrado. Análogamente a como se hacían las operaciones de inserción, se puede proceder de dos formas:
-
Borrado de valores usando
dbWriteTable()con sobreescritura: esto implica extraer todos los datos de la tabla, borrar el registro o los registros correspondientes y sobreescribir nuevamente la tabla en la base de datos mediante la instruccióndbWriteTable()con la opciónoverwrite = TRUE; para ver el resultado se puede usar la funciónsummary(). El siguiente fragmento de código muestra cómo hacerlo:
dfDatos_Prueba <- dbReadTable(mibbdd, "DatosPrueba")
dfDatos_Prueba <- dfDatos_Prueba[dfDatos_Prueba$CodPrueba < 25, ]
dbWriteTable(mibbdd, "DatosPrueba", dfDatos_Prueba, overwrite = TRUE, row.names =FALSE)
#> [1] TRUE-
Borrado de registros con consulta SQL en
dbSendQuery(): se puede llevar a cabo utilizando una sentencia SQL de borradodelete49 con la instruccióndbSendQuery()para borrar registros de la base de datos. El siguiente fragmento de código muestra cómo hacerlo:
# Se usa una sentencia SQL de borrado. El criterio de borrado es completamente arbitrario a efectos ilustrativos.
SentenciaSQL_Eliminación ="delete from DatosPrueba where CodPrueba > 10"
dbSendQuery (mibbdd, SentenciaSQL_Eliminación)
#> <MySQLResult:1,0,30>Finalmente, si fuera necesario eliminar toda la tabla, se podría usar una sentencia drop table:50
dbSendQuery(mibbdd, "drop table DatosPrueba")
#> <MySQLResult:0,0,31>
dbDisconnect(mibbdd)
#> [1] TRUEResumen
En este capítulo se han presentado los fundamentos de las bases de datos relacionales. Es importante tener presentes los siguientes aspectos:
Los datos en las bases de datos se corresponden a valores de atributos relevantes de entidades del mundo real.
Los datos de una base de datos son una percepción u observación del mundo real.
Los datos son la materia prima de los procesos de negocio.
Los sistemas de información dan soporte a los procesos de negocio.
Los datos son un elemento fundamental de los sistemas de información.
SQL es el lenguaje más comúnmente utilizado en operaciones sobre el modelo físico de bases de datos relacionales.
SQL se puede utilizar como Lenguaje de Definición de Datos (LDD), como Lenguaje de Manipulación de Datos (LMD) y como Lenguaje de Administración de Datos (LAD).
La sintaxis de SQL depende fuertemente del sistema gestor de bases de datos relacionales que lo implemente.
R software, a través del driver específico, permite manejar bases de datos implementando las operaciones CRUD.