Capítulo 26 Clasificador \(k\)-vecinos más próximos
Ramón A. Carrasco\(^{a}\), Itzcóatl Bueno\(^{a,b}\) y José-María Montero\(^{c}\)
\(^{a}\)Universidad Complutense de Madrid
\(^{b}\)Instituto Nacional de Estadística
\(^{c}\)Universidad de Castilla-La Mancha
26.1 Introducción
El k-vecinos más próximos (KNN, por sus siglas en inglés k-nearest neighbors) es un algoritmo de aprendizaje no paramétrico. Los algoritmos no paramétricos no presuponen la forma concreta del modelo a entrenar, lo que les dota de una enorme flexibilidad. Sin embargo, como contrapartida, necesitan más datos de entrenamiento, lo que se traduce en que son más lentos que los algoritmos paramétricos. Al contrario que otros algoritmos de aprendizaje que permiten deshacerse de los datos de entrenamiento una vez se entrena el modelo, el modelo KNN guarda las observaciones de entrenamiento en la memoria. Esto es, al incorporar una nueva observación \({\bf{x}}_j\), el algoritmo KNN encuentra las \(k\) observaciones del conjunto de datos de entrenamiento más parecidas a la nueva y proporciona como salida (predicción) la clase de la variable respuesta a la que pertenecen la mayor parte de las k observaciones (cuando se trata de un problema de clasificación) o el valor medio de la variable respuesta en dichas \(k\) observaciones (en el caso de que el problema sea de regresión).
El número de casos (\(k\)) a utilizar para clasificar las nuevas observaciones es un parámetro crucial en este algoritmo (James et al., 2013). Si, por ejemplo, \(k=3\), el modelo KNN utiliza las tres observaciones más parecidas (vecinas) al nuevo caso para clasificarlo. Es recomendable probar distintos valores de \(k\) para conseguir el mejor ajuste del modelo. No obstante, es conveniente evitar valores extremos de \(k\) porque valores muy bajos de \(k\) aumentarán la variabilidad y conducirán a clasificaciones erróneas, mientras que valores muy elevados de \(k\) harán que el algoritmo sea computacionalmente costoso y, además, tampoco llevarán a buenas clasificaciones (por ejemplo, en el caso de regresión, si el valor de \(k\) está cerca del número de observaciones, la predicción para cualquier observación nueva siempre será un valor muy cercano a la media de la variable respuesta en el conjunto de datos de entrenamiento). Además, también se recomienda establecer valores impares de \(k\) para evitar, en el caso clasificatorio, puntos muertos estadísticos (empate entre categorías de la variable respuesta, por lo que no se puede decidir cuál es la mayoritaria).
A modo de ejemplo, en la Fig. 26.1, tanto con \(k=3\) como con \(k=7\) la nueva observación se clasifica en la categoría roja, puesto que esta es la mayoritaria en ambos casos.
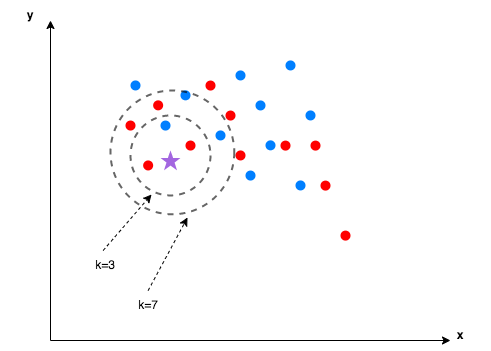
Figura 26.1: Ejemplo de \(k\)-vecinos más próximos.
La escala de las variables puede desvirtuar el resultado del modelo KNN. Por ello, el conjunto de datos debe escalarse para que las variables con unidades de medida grandes no tengan más importancia en el cálculo de la similitud entre las observaciones que las que tienen magnitudes menores. De esta manera desaparece el efecto “escala” o “unidades de medida” y se estandariza la varianza.
Pese a que el modelo KNN es fácil de entender y generalmente preciso, almacenar el conjunto de datos de entrenamiento, así como calcular la distancia entre cada nueva observación a clasificar y las observaciones del conjunto de datos, exige elevados recursos computacionales. Esto implica que cuanto mayor es la cantidad de observaciones en el conjunto de datos, mayor es el tiempo de ejecución para obtener una única predicción, lo cual puede dar lugar a tiempos de procesamiento grandes. Por este motivo, no se recomienda el uso del algoritmo KNN con conjuntos de datos muy grandes. Otra desventaja a tener en cuenta es la dificultad de aplicar KNN a conjuntos de datos con un gran número de variables, puesto que calcular las distancias entre observaciones con múltiples dimensiones también incrementa la necesidad de recursos computacionales y podría dificultar la obtención de clasificaciones y predicciones precisas (en el caso de que la variable respuesta sea numérica).
26.2 Decisiones a tener en cuenta
La elección de la función de distancia, así como el número de vecinos, \(k\), son decisiones que debe tomar el investigador antes de ejecutar el algoritmo. Este último es el hiperparámetro del modelo, cuyo valor devuelve la función modelLookup() de caret:
modelLookup("knn")
model parameter label forReg forClass probModel
1 knn k #Neighbors TRUE TRUE TRUE26.2.1 Función de distancia a utilizar
El grado de “vecindad” entre dos observaciones con predictores cuantitativos se mide a través de una función de distancia. En el proceso de entrenamiento del algoritmo KNN, generalmente se utiliza la distancia euclídea, mostrada en la ecuación (26.1), o la distancia de Manhattan, que puede verse en la ecuación (26.2). En caso de que haya predictores cuantitativos y cualitativos (o solo cualitativos) el coeficiente de Gower es una buena opción, como muestra la ecuación (26.3). No obstante, también pueden utilizarse otras funciones de distancia. Un buen número de ellas puede verse en el Cap. 30.
Sean dos observaciones \(p\)-dimensionales, \({\bf{x}}_r\) y \({\bf{x}}_s\):
- Distancia euclídea. Se define como:
\[\begin{equation} \tag{26.1} d_{e}({\bf x}_r;{\bf{x}}_{s})=\sqrt{\sum_{k=1}^{p}\left( x_{rk}-x_{sk}\right) ^{2}}. \end{equation}\]
Ignora las unidades de medida de las variables y, en consecuencia, aunque es invariante a los cambios de origen, no lo es a los cambios de escala. También ignora las relaciones entre ellas. Resulta de utilidad con variables cuantitativas incorrelacionadas y medidas en las mismas unidades.
- Distancia Manhattan o city block. Se define como:
\[\begin{equation} \tag{26.2} d_{MAN}({\bf x}_r;{\bf{x}}_{s})=\sum_{k=1}^{p}\left\vert x_{rk}-x_{sk}\right\vert. \end{equation}\]
Le afectan las diferentes escalas de las variables y es menos sensible que la distancia euclídea a los valores extremos. Por ello, es recomendable cuando las variables son cuantitativas, con las mismas unidades de medida (o escaladas), sin relaciones entre ellas y con valores extremos.
- Si no todas las variables son cuantitativas, se utiliza la medida de similaridad de Gower:
\[\begin{equation} \tag{26.3} S_{rs}({\bf x}_r;{\bf{x}}_{s})=\frac{\sum_{k=1}^{p}s_{rs}}{\sum_{k=1}^{p}w_{rs}}, \end{equation}\]
donde \(w_{rs}\) vale siempre la unidad, salvo para variables binarias si los dos elementos presentan el valor cero. En cuanto al valor de \(S_{rs}\), se distinguen tres casos:
- Variables cualitativas de más de dos niveles: 1 si ambos elementos son iguales en la *k*-ésima variable; 0 si son diferentes.
- Variables dicotómicas: 1 si la variable considerada está presente en ambos elementos; 0 en los demás casos.
- Variables cuantitativas: $1-\frac {|x_{ik}-x_{jk}|}{R_k}$, donde $R$ es el rango de la variable *k*.No es recomendable cuando las variables cuantitativas sean muy asimétricas. En este caso, hay dos procedimientos aproximados: \((i)\) calcular medidas separadas para las variables cuantitativas y cualitativas y combinarlas estableciendo algún tipo de ponderación (véase Cap. 30); \((ii)\) pasar las variables cuantitativas a cualitativas y utilizar las medidas propuestas para este tipo de variables (véase también Cap. 30).
26.2.2 Número de vecinos (k) seleccionados
Como ya se ha avanzado, la elección del número de vecinos (\(k\)) que intervienen en el ajuste del algoritmo es determinante para su rendimiento. Si se escogen demasiado pocos vecinos, se producirá sobreajuste en el modelo. En el caso extremo en el que solo se utilizase un vecino (\(k=1\)), la predicción se basará únicamente en la observación con la menor distancia al elemento a clasificar. Por otro lado, un número alto de vecinos hace que el modelo no ajuste bien al tener en cuenta un vecindario demasiado grande. En este sentido, en el caso extremo de considerar como vecinas todas las observaciones disponibles (\(k=n\)), sea cual sea la nueva observación, la predicción siempre será el valor medio de la variable respuesta en el conjunto de datos (en el caso de la regresión) o la clase mayoritaria de la variable respuesta en dicho conjunto (en el caso de la clasificación).
No existe una regla general para la elección óptima de \(k\), puesto que en gran medida dependerá del conjunto de datos utilizado. Cuando el conjunto de datos tiene pocas variables que no aportan información, valores pequeños de \(k\) tienden a funcionar mejor. Cuantas más variables sin importancia se incluyen en el conjunto predictores, mayor deberá ser el valor de \(k\) para suavizar su efecto, es decir, para reducir el ruido que incorporan dichas variables, que no aportan información nueva para mejorar el modelo.
26.3 Procedimiento con R: la función knn()
En el paquete class de R se encuentra la función knn() que se utiliza para entrenar el modelo k-vecinos más próximos:
knn(train, test, cl, k = 1, ...)-
train: conjunto de datos con las observaciones de entrenamiento. -
test: conjunto de datos con las observaciones de validación. Un vector se interpreta como una única observación a validar. -
cl: clases de las observaciones de entrenamiento. -
k: número de vecinos a considerar
26.4 Aplicación del modelo KNN en R
Para llevar a cabo la aplicación en la que se centra esta sección se retoma el ejemplo expuesto en los dos capítulos precedentes relativo a la empresa Beauty eSheep, que pretende vender tensiómetros digitales, obteniéndose las predicciones sobre si el cliente comprará o no un tensiómetro en función de una serie de características del cliente (en este caso, todas ellas cuantitativas) que actúan como variables predictoras y que se encuentran, junto con la variable respuesta, en el conjunto de datos dp_entr_NUM, incluido en el paquete CDR, y que se resume en la Tabla 24.8.
Dado que todas las variables predictoras son cuantitativas y que tienen distintas escalas de medida (euros, años, unidades, etc.) es necesario indicar en la función trainControl() que se haga un preprocesamiento para estandarizarlas. Además, se define como método de validación (con remuestreo) el de validación cruzada con 10 grupos con repetición (véase Cap. 10).
library("CDR")
library("class")
library("caret")
library("reshape")
library("ggplot2")
data(dp_entr_NUM)
head(dp_entr_NUM)
ind_pro11 ind_pro12 ind_pro14 ind_pro15 ind_pro16 ind_pro17 des_nivel_edu.ALTO
1 1 0 1 1 1 0 0
2 0 0 1 0 1 0 0
3 0 0 1 1 1 1 0
4 0 1 1 0 0 0 0
5 0 1 1 0 1 0 0
6 1 0 1 0 0 0 1
des_nivel_edu.BASICO des_nivel_edu.MEDIO importe_pro11 importe_pro12 importe_pro14
1 0 1 157 0 40
2 0 1 0 0 240
3 1 0 0 0 425
4 0 1 0 120 60
5 1 0 0 120 133
6 0 0 115 0 220
importe_pro15 importe_pro16 importe_pro17 edad tamano_fam anos_exp ingresos_ano CLS_PRO_pro13
1 200 180 0 49 4 24 30000 S
2 0 180 0 38 2 12 53000 N
3 200 180 300 61 4 37 172000 S
4 0 0 0 47 3 21 38000 N
5 0 180 0 34 1 10 38000 N
6 0 0 0 43 2 18 60000 N
# Definimos un método de remuestreo
cv <- trainControl(
method = "repeatedcv",
number = 10,
repeats = 5,
classProbs = TRUE,
preProcOptions = list("center"),
summaryFunction = twoClassSummary
)En cuanto a la selección del hiperparámetro \(k\), en el paquete caret de R se puede definir una red de posibles valores sobre los que evaluar el modelo KNN, determinándose automáticamente el valor que mejor rendimiento proporciona. A continuación se definen los posibles valores de \(k\) que se quieren evaluar.
# Definimos la red de posibles valores del hiperparámetro
hyper_grid <- expand.grid(k = c(1:10,15,20,30,50,75,100))Una vez que se han definido tanto el método de validación repetida con remuestreo como la red de posibles valores del hiperparámetro se procede a entrenar el modelo:192
set.seed(101)
# Se entrena el modelo ajustando el hiperparámetro óptimo
model <- train(
CLS_PRO_pro13 ~ .,
data = dp_entr_NUM,
method = "knn",
trControl = cv,
tuneGrid = hyper_grid,
metric = "ROC"
)# se muestra la salida del modelo
model
k-Nearest Neighbors
558 samples
17 predictor
2 classes: 'S', 'N'
No pre-processing
Resampling: Cross-Validated (10 fold, repeated 5 times)
Summary of sample sizes: 502, 502, 502, 503, 503, 502, ...
Resampling results across tuning parameters:
k ROC Sens Spec
1 0.6584524 0.6466402 0.6702646
2 0.6769109 0.6179101 0.6131217
3 0.6828893 0.6216402 0.6496561
4 0.6851087 0.6404233 0.6394709
5 0.6951129 0.6540212 0.6666138
6 0.6914664 0.6216402 0.6543386
7 0.6982592 0.6252381 0.6953439
8 0.6974556 0.6281481 0.6960053
9 0.6992229 0.6159524 0.7117725
10 0.6994133 0.6037037 0.7052910
15 0.6875879 0.5749206 0.7232011
20 0.6731477 0.5722751 0.7010582
30 0.6752986 0.5529630 0.7024603
50 0.6890259 0.5163757 0.7605556
75 0.6852886 0.5092593 0.7670106
100 0.6719378 0.5049471 0.7820106
ROC was used to select the optimal model using the largest value.
The final value used for the model was k = 10.En los resultados mostrados, para cada valor de \(k\) se toman 10 muestras con 500 observaciones en el conjunto de entrenamiento y 50 en el de test. Dichas 500 y 50 observaciones van rotando de modelo a modelo para tener 10 distintos. Los valores ROC, Sens y Spec que aparecen en los resultados son la media de los obtenidos en esos 10 modelos.
Tanto en los resultados mostrados como en la Fig. 26.2, se observa que el número óptimo de vecinos es \(k=10\), número de vecinos para el cual se alcanza el rendimiento óptimo del modelo (el mayor valor del área bajo la curva ROC, cuya sigla es AUC). Una vez determinado el número de vecinos óptimos, el modelo seleccionado utiliza todos los datos (en este caso \(550=500+50\)) para clasificar una nueva observación.
ggplot(model) +
geom_vline(xintercept = unlist(model$bestTune),col="red",linetype="dashed") +
theme_light()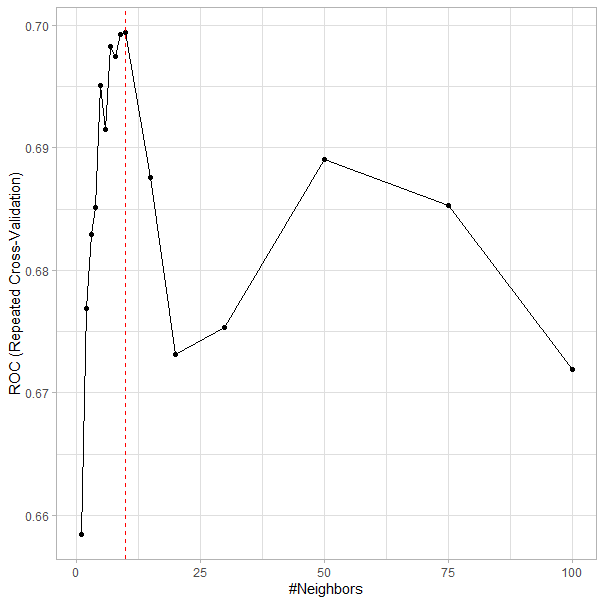
Figura 26.2: Número óptimo de vecinos (\(k\)).
El box plot de los resultados obtenidos durante el proceso de validación cruzada (Fig. 26.3) muestra que el AUC del modelo oscila entre un 60% y un 85% aproximadamente.
ggplot(melt(model$resample[,-4]), aes(x = variable, y = value, fill=variable)) +
geom_boxplot(show.legend=FALSE) +
xlab(NULL) + ylab(NULL)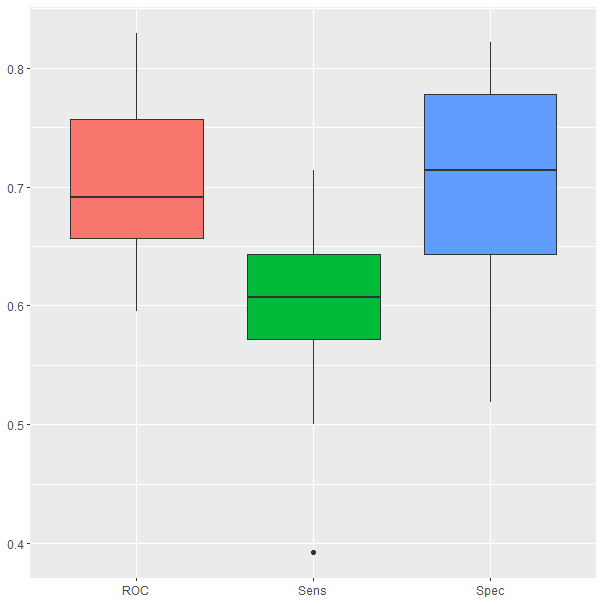
Figura 26.3: Resultados obtenidos durante el proceso de validación cruzada.
El modelo se resiente en su rendimiento al tener dificultades en clasificar correctamente la clase positiva; más concretamente se puede observar en la Fig. 26.3 que la sensibilidad oscila entre el 40% y el 75%, resultados ligeramente peores que los que obtienen al clasificar observaciones de la clase negativa, los cuales oscilan entre el 50% y el 85%.
La matriz de confusión para \(k=10\), así como las medidas que se derivan de ella, se presentan en los siguientes resultados:
set.seed(101)
confusionMatrix(predict(model), dp_entr_NUM$CLS_PRO_pro13)Confusion Matrix and Statistics
Reference
Prediction S N
S 186 65
N 93 214
Accuracy : 0.7168
95% CI : (0.6775, 0.7539)
No Information Rate : 0.5
P-Value [Acc > NIR] : < 2e-16
Kappa : 0.4337
Mcnemar's Test P-Value : 0.03171
Sensitivity : 0.6667
Specificity : 0.7670
Pos Pred Value : 0.7410
Neg Pred Value : 0.6971
Prevalence : 0.5000
Detection Rate : 0.3333
Detection Prevalence : 0.4498
Balanced Accuracy : 0.7168
'Positive' Class : S donde la clase positiva es la compra del tensiómetro digital y la negativa, la no compra de dicho producto.
El valor predictivo positivo muestra que el modelo clasifica a 251 clientes como compradores del tensiómetro digital, si bien solo el 74,10% de estas clasificaciones es correcto. El valor predictivo negativo indica que de los 307 clientes que el modelo predijo como no compradores, tan solo el 69,71% realmente lo son (214 de ellos). Calculando ahora los porcentajes por columnas, la sensibilidad indica que el modelo ha sido capaz de clasificar correctamente al 66,67 % de los clientes compradores del tensiómetro, esto es, a 186 de los 279 que figuran como compradores en el conjunto de entrenamiento. Por otro lado, la especificidad indica que el 76,7% de los clientes que en el conjunto de entrenamiento pertenecían a la clase negativa (no compradora del tensiómetro) ha sido clasificado correctamente (214 de 279).
Resumen
En este capítulo se introduce al lector en el algoritmo de aprendizaje supervisado conocido como k-vecinos más próximos, destacando:
las decisiones a tener en cuenta antes de entrenar el modelo,
las distancias más utilizadas en el entrenamiento del modelo,
las ventajas y desventajas del número de vecinos a tener en cuenta en labores de clasificación o prediccion.