Capítulo 57 Implementación de un sistema experto en el ámbito pediátrico
Arturo Peralta\(^{a,b,c}\), José Ángel Olivas\(^{c}\) y Eusebio Angulo\(^{c}\)
\(^{a}\)Universidad Internacional de Valencia
\(^{b}\)Universidad Internacional de la Rioja
\(^{c}\)Universidad de Castilla-La Mancha
57.1 Introducción
Sin lugar a duda, el análisis de situaciones complejas para la evaluación y toma de decisiones es un proceso para el que tradicionalmente se requiere el apoyo de un especialista dispuesto a poner en uso todo su conocimiento. Sin embargo, el desarrollo de sistemas automáticos capaces de modelar y procesar el conocimiento que un experto pudiera tener sobre un ámbito concreto para dar una respuesta adecuada a una consulta relacionada está cada día más extendido como mecanismo de ayuda. A este tipo de herramientas se les denomina sistemas expertos (SE).
En este capítulo se introducen los conceptos teóricos fundamentales de la ingeniería del conocimiento, los componentes y el funcionamiento de los SE para, posteriormente, presentar cómo su aplicación puede apoyar en el proceso de evaluación clínica en el ámbito pediátrico de atención primaria. Finalmente, se incluye una sencilla implementación en R de un SE enfocado a la ayuda en esta problemática.
57.2 Marco teórico
Un SE es un programa de ordenador que trata de emular el comportamiento de una persona experta en un dominio de conocimiento específico ante un problema que se plantee en dicho dominio y cómo llega a su solución. La ingeniería del conocimiento se ocupa, entre otras cosas, del proceso de especificación, análisis y desarrollo de un sistema experto (Martínez et al., 2005).
Los principales componentes de un SE son: \((i)\) la base de hechos (BH), que contiene la definición del entorno sobre el que se van a resolver problemas. Hace el papel de “ojos” del SE; \((ii)\) la base de conocimientos (BC), que contiene la información del dominio específico, convenientemente representado, capaz de resolver problemas. También puede considerar la representación de incertidumbre; \((iii)\) el motor de inferencias, que es el proceso de razonamiento que usa el SE. Combina hechos y conocimiento para emitir una conclusión; y \((iv)\) la interfaz de entrada/salida para comunicarse con los usuarios y/o expertos.
En la Fig. 57.1 se muestra un diagrama con los principales componentes de un SE.
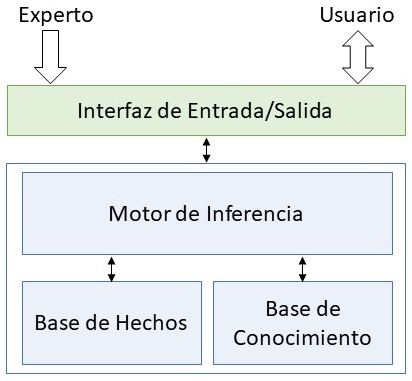
Figura 57.1: Componentes de un sistema experto.
Las principales limitaciones en la construcción de un SE vienen dadas porque el conocimiento experto humano es experiencia compilada, es heurístico, esto es, basado en experiencia y en reglas prácticas. Además, es incompleto, impreciso e incierto y, a veces, inconsistente y con errores o imprecisiones. Es por ello que las limitaciones de todo SE pueden ser que no conoce lo que conoce ni el porqué, carece de imaginación, emociones, inteligencia innata, sentido común, etc. Tiene poco conocimiento de sí mismo, del usuario y del contexto de cada interacción y capacidad de razonamiento limitada por su estrategia de construcción.
En este contexto, los sistemas de producción son modelos de cálculo que han probado su eficiencia en la ingeniería del conocimiento, tanto en el desarrollo de algoritmos de búsqueda como en el modelado de problemas del dominio humano. Sus componentes principales son:
- Las reglas de producción, que son la forma más extendida de representar el conocimiento, constan de condiciones (hipótesis) y acciones (conclusiones) y tienen la forma:
Si (If)
Condición 1
y Condición 2
...
y Condición n
Entonces (Then)
Conclusión 1
Conclusión 2
...
y Conclusión mPor ejemplo:
Si
ha fallado la bombilla
y hay una de repuesto
y está útil
Entonces
cambiar la bombilla por la de repuesto
y seguir trabajandoLa memoria de trabajo, que contiene una descripción del estado actual del mundo o entorno de la aplicación en cada paso del proceso de razonamiento. Esta descripción es un modelo que sirve para asociar los antecedentes de las reglas con las observaciones del mundo, con el objetivo de seleccionar o producir las acciones apropiadas. En el momento en que se cumplen todas las condiciones de una regla se produce el “disparo” de la misma, ejecutándose la acción. Esta operación altera el contenido de la memoria de trabajo.
El ciclo de reconocimiento y actuación, que es el procedimiento de control de un sistema de producción. Es un procedimiento feedforward o hacia delante. La memoria de trabajo se inicializa con la descripción del problema. Los modelos almacenados en la memoria de trabajo se tratan de superponer en las condiciones de las producciones. Tras ello, se crea un conjunto “conflicto”, es decir, un subconjunto de producciones cuyas condiciones se cumplen. Se escoge una producción y se “dispara” o se activa. Se repite todo el proceso descrito con la memoria de trabajo modificada. El proceso continúa hasta que no haya condiciones en las reglas que cumplan el contenido de los modelos de la memoria de trabajo.
Una de las principales ventajas de los sistemas de producción en los SE es la separación del conocimiento y del control. Se pueden hacer cambios fáciles de reglas sin cambiar el control y viceversa. Otras dos son la modularidad de las reglas de producción y la independencia del lenguaje de programación usado.
57.2.1 Razonamiento
El razonamiento se define como el proceso de obtención de inferencias o conclusiones a partir de unos hechos u observaciones reales o asumidos y de un conocimiento previo. La inferencia es el proceso por el que, a partir de unos hechos conocidos, se obtienen conclusiones acerca de otros desconocidos (Amparo & Guijarro, 2004; Fleitas, 2017). La realización de este tipo de procesamiento es llevada a cabo por el denominado motor de inferencia.
El razonamiento automático ya se utilizaba en los años 50 en los juegos. En 1963 se presentó el sistema General Problem Solver, capaz de hacer inferencias lógicas (Newell et al., 1974). En un SE se distinguen dos tipos de razonamiento automático:
Forward chaining (encadenamiento hacia delante, deductivo, progresivo, dirigido por datos o hechos):
síntomas $\rightarrow$ causas. Se parte de sentencias (reglas de inferencia) de la BC para producir conclusiones o afirmaciones. Se denomina también procedimiento data driven.Backward chaining (encadenamiento hacia atrás, inductivo, regresivo, dirigido por metas u objetivos):
síntomas $\leftarrow$ causas. Se parte de una hipótesis a contrastar proporcionando reglas en la BC de forma retroactiva para analizar las asertivas que soportan dicha hipótesis.
Los pasos del motor de inferencia son los siguientes:
Elaboración de un conjunto conflicto con todas las reglas cuyas condiciones se cumplen;
detección (filtro) de reglas pertinentes o selección de reglas a partir de unos hechos. Se trata de obtener de la BC el conjunto de reglas aplicables en una situación determinada o estado de la BH;
aplicación de reglas o resolución del conflicto. Consiste en seleccionar una regla del conjunto conflicto y dispararla (ejecutar su conclusión). Se altera la BH o memoria de trabajo incluyendo el consecuente de la regla “disparada”;
vuelta al paso 1 hasta que el conjunto conflicto esté vacío.
El ciclo de “razonamiento hacia delante” se sintetiza en los siguientes pasos:
Parte de unas observaciones (hechos);
a partir de los hechos observados, se seleccionan las reglas cuyas condiciones están relacionadas con estos;
las reglas seleccionadas son examinadas para ver si cumplen todas sus condiciones. Aquellas que las verifican constituyen el conjunto conflicto;
del total de reglas que forman el conjunto conflicto se selecciona una sola y se activa (se “dispara”). La selección de una regla del conjunto conflicto se denomina resolución del conflicto;
la activación de la regla provoca la aparición de otros hechos que se añaden a los observados y se actualiza la base de hechos;
vuelta al paso 2 hasta analizar todos los hechos observados y deducidos.
En la Fig. 57.2 se muestra el algoritmo correspondiente al ciclo de inferencia hacia delante.
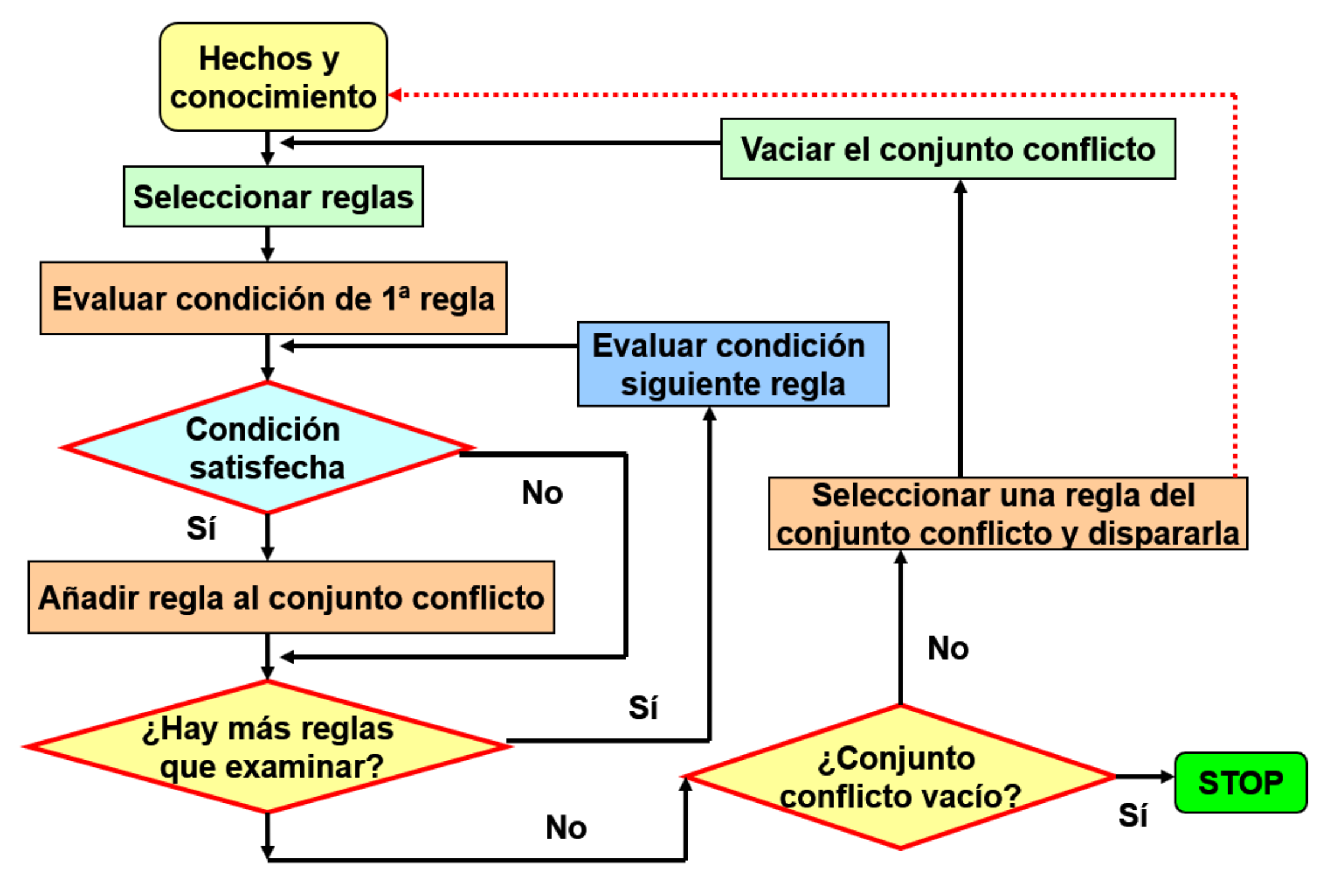
Figura 57.2: Ciclo de razonamiento hacia delante.
57.3 Sistema experto para el ámbito pediátrico en atención primaria
57.3.1 El caso de uso
En la actualidad, uno de los principales problemas al que se enfrentan los profesionales de la sanidad en el ámbito pediátrico de atención primaria en España es la falta del tiempo suficiente para realizar una evaluación clínica del estado del paciente. La necesidad de un mayor número de médicos especialistas y la aparición de picos de demanda motivados por fenómenos como el COVID-19, o de modo estacional por otras enfermedades recurrentes, favorecen esta situación.
Ante esta problemática, los centros de salud tratan de optimizar sus recursos mediante diferentes vías, poniendo especial interés en realizar procesos de triaje que les permitan priorizar la atención a los pacientes según su nivel de urgencia. Para ello, en España se utilizan escalas como el Manchester Triage System (MTS), el Sistema Español de Triaje (SET) y el Canadian Pediatric Triage and Acuity Scale (CPTAS) (Soler et al., 2010) para establecer el tiempo que un paciente puede esperar para recibir atención médica en base a sus síntomas y evolución.
Sin embargo, realizar un correcto proceso de triaje, además de requerir de un gran conocimiento experto, hace necesario un tiempo para una evaluación clínica que a veces resulta difícil dedicar. En este contexto, se plantea el desarrollo de un SE capaz de ayudar en el proceso de evaluación médica, con el objetivo de facilitar el proceso de triaje.
57.3.2 La implementación del sistema experto
El primer paso para el desarrollo de un SE es la definición de un conjunto de reglas que modelen el conocimiento con el que se nutrirá. Para ello, es posible recurrir al apoyo de expertos, capaces de definir su conocimiento como reglas, o la aplicación de mecanismos de extracción de conocimiento a partir del procesamiento de conjuntos de datos y sucesos.
En este ejemplo, se recopiló y procesó un conjunto de datos relativos a los motivos de consulta pediátrica en un centro de salud, donde la escala de triaje utilizada fue el CPTAS. Los datos fueron anonimizados, seleccionando únicamente aquellos campos que pudieran resultar clave para la extracción de conocimiento y la conformación de reglas. Adicionalmente, se contó con el apoyo de profesionales especialistas del ámbito pediátrico para revisar y complementar algunas de las reglas extraídas. Un fragmento de los datos utilizados para el proceso de extracción de reglas se muestra en la Tabla 57.1.
| Sexo | Edad | Tiempo evolución | Causa | Triaje |
|---|---|---|---|---|
| Hombre | 1-3 años | 25-72 horas | Dermatológica | 5 (120 minutos) |
| Mujer | 1-3 años | 25-72 horas | Respiratoria | 3 (30 minutos) |
| Hombre | 4-6 años | 7-12 horas | Gastrointestinal | 5 (120 minutos) |
| Hombre | 4-6 años | 2-6 horas | Ocular | 4 (60 minutos) |
| Mujer | 4-6 años | 13-24 horas | Fiebre | 5 (120 minutos) |
A partir del procesamiento de un total de 400 visitas médicas mediante el algoritmo de extracción de reglas de asociación “Magnum Opus”, basado en la definición original de Webb (2011) y con el conocimiento experto proporcionado por un panel de pediatras, se extrajo un conjunto de reglas con suficiente calidad. A continuación se muestran, a modo de ejemplo, \(10\) de ellas:
R1: Si Causa Ginecológica o Edad mayor de 12 años \(\rightarrow\) Tiempo de Evolución mayor de 73 h.
R2: Si Causa Ginecológica \(\rightarrow\) Sexo Mujer.
R3: Si Edad menor de 7 días o Causa Fiebre \(\rightarrow\) Tiempo de evolución de 1 h.
R4: Si Edad mayor de 12 años y Tiempo de Evolución mayor de 73 h \(\rightarrow\) Causa Respiratoria.
R5: Si Tiempo Evolución mayor de 73 h y Causa Ocular \(\rightarrow\) Triaje 1.
R6: Si Causa Respiratoria y Sexo Mujer \(\rightarrow\) Triaje 3.
R7: Si Tiempo de Evolución entre 2-6 h o Causa Neurológica \(\rightarrow\) Triaje 2.
R8: Si Causa Respiratoria y Tiempo de Evolución entre 2-6h \(\rightarrow\) Triaje 4.
R9: Si Tiempo de Evolución es 13-24 h y Causa Ginecológica y Sexo Mujer \(\rightarrow\) Triaje 5.
R10: Si Tiempo de Evolución mayor de 73 h \(\rightarrow\) Triaje 4.
A continuación, se muestra el código en R para la implementación de un SE capaz de procesar reglas como las anteriores, realizando una ejecución para obtener el valor de triaje correspondiente. Para este ejemplo se considera una niña mayor de \(12\) años de edad cuyo motivo de consulta es ginecológico, con un tiempo de evolución superior a \(73\) horas.
Es importante señalar que, normalmente, un SE parte de una BH compuesta por decenas o cientos de reglas. No obstante, para simplificar el siguiente fragmento de código, se considera únicamente la carga de \(10\) reglas a modo de ejemplo.
Se declaran las reglas que conformarán la base conocimiento del SE:
La BC del SE contiene 10 reglas.
Cada regla se modela como una lista de antecedentes y un consecuente.
La relación entre los consecuentes se modela con el atributo “operador” del siguiente modo:
1 = Y lógico, 0 = O lógico, -1 = no hay operaciones.
r1 <- list(
antecedentes = list("Causa_Ginecologica", "Edad_>12a"),
consecuente = list("TiempoEvolucion_>73h"), operador = 0
)
r2 <- list(
antecedentes = list("Causa_Ginecologica"),
consecuente = list("Sexo_Mujer"), operador = -1
)
r3 <- list(
antecedentes = list("Edad_<7d", "Causa_Fiebre"),
consecuente = list("TiempoEvolucion_1h"), operador = 0
)
r4 <- list(
antecedentes = list("Edad_>12a", "TiempoEvolucion_>73h"),
consecuente = list("Causa_Respiratoria"), operador = 1
)
r5 <- list(
antecedentes = list("TiempoEvolucion_>73h", "Causa_Ocular"),
consecuente = list("Triaje_1"), operador = 1
)
r6 <- list(
antecedentes = list("Causa_Respiratoria", "Sexo_Mujer"),
consecuente = list("Triaje_3"), operador = 1
)
r7 <- list(
antecedentes = list("TiempoEvolucion_2-6h", "Causa_Neurologica"),
consecuente = list("Triaje_2"), operador = 0
)
r8 <- list(
antecedentes = list("Causa_Respiratoria", "TiempoEvolucion_2-6h"),
consecuente = list("Triaje_4"), operador = 1
)
r9 <- list(
antecedentes = list("TiempoEvolucion_13-24h", "Causa_Ginecologica", "Sexo_Mujer"),
consecuente = list("Triaje_5"), operador = 1
)
r10 <- list(
antecedentes = list("TiempoEvolucion_>73h"),
consecuente = list("Triaje_4"), operador = -1
)
# r1 regla completa
# r1[1] lista antecedentes
# r1[[1]] [1] primero de los antecedentes
# r1[2] lista consecuentes
# r1[[2]] [1] primero de los consecuentes
b_hechos <- list("Causa_Ginecologica", "Edad_>12a", "TiempoEvolucion_>73h")Se inicializa la BC con el conjunto de reglas y la BH con la circunstancia a evaluar:
# Se añaden todas las reglas a la Base de Conocimiento
b_conocimiento <- list(r1, r2, r3, r4, r5, r6, r7, r8, r9, r10)Se define una función para comprobar la existencia de un número en una lista. Esta función será usada por el motor del SE:
# Función para comprobar si una lista contiene un número
contiene <- function(numero, lista) {
existe <- FALSE
if (length(lista) > 0) {
for (i in 1:length(lista)) {
if (numero == lista[[i]]) existe <- TRUE
}
}
return(existe)
}Se implementa el motor del SE: el algoritmo ejecuta un bucle en el que, en cada iteración, evalúa las reglas disponibles contenidas en la BC. Considerando los ítems de la BH, si una regla puede ser “disparada” se añade al conjunto conflicto. La regla “disparada” en una iteración será la primera disponible en el conjunto conflicto. Este se inicializa en cada iteración. El consecuente de la regla “disparada” se añade a la BH. Cada regla solo puede “dispararse” una vez, por lo que se actualiza una lista de reglas “disparadas”. El algoritmo finaliza cuando el conjunto conflicto queda vacío, al haber sido “disparadas” todas las reglas o no existir más candidatas a ser “disparadas”.
# Motor del Sistema Experto
AlgoritmoSE <- function(b_hechos, b_conocimiento) {
c_conflicto <- list()
r_disparadas <- list()
condicion <- TRUE
iteracion <- 0
while (condicion) {
c_conflicto <- list()
cat("Iteración: ", iteracion, "\n")
iteracion <- iteracion + 1
for (i in 1:length(b_conocimiento)) {
if (!contiene(i, r_disparadas)) {
if (b_conocimiento[[i]][[3]][[1]] == 1) {
r_disparada <- TRUE
} else {
r_disparada <- FALSE
}
for (j in 1:length(b_conocimiento[[i]][[1]])) {
antecedente <- FALSE
for (k in 1:length(b_hechos)) {
if (b_conocimiento[[i]][[1]][[j]] == b_hechos[[k]]) {
if (b_conocimiento[[i]][[3]][[1]] == 0 || b_conocimiento[[i]][[3]][[1]] == -1) r_disparada <- TRUE
antecedente <- TRUE
}
}
if (b_conocimiento[[i]][[3]][[1]] == 1) {
if (!antecedente) r_disparada <- FALSE
}
}
if (r_disparada) {
cat("Regla", i, "añadida a Conjunto conflicto\n")
c_conflicto[length(c_conflicto) + 1] <- i
}
}
}
if (length(c_conflicto) > 0) {
# str("Conjunto conflicto:")
# str(c_conflicto)
r_disparadas[length(r_disparadas) + 1] <- c_conflicto[1]
cat("Regla", r_disparadas[[length(r_disparadas)]], "disparada\n")
b_hechos[length(b_hechos) + 1] <- b_conocimiento[[r_disparadas[[length(r_disparadas)]]]][[2]][[1]]
str("Base de hechos:")
str(b_hechos)
cat("Consecuente:", b_conocimiento[[r_disparadas[[length(r_disparadas)]]]][[2]][[1]], "\n")
} else {
condicion <- FALSE
}
}
}57.3.3 Puesta en marcha del sistema experto
Ahora considérese, por ejemplo, una posible paciente con más de 12 años de edad, que acude a consulta por causa ginecológica con un tiempo de evolución de los síntomas mayor de 73 h. ¿Qué triaje le corresponde? Para responder esta pregunta, se inicializa la BH con la situación propuesta (Causa_Ginecologica, Edad_>12a y TiempoEvolucion_>73h):
# Se inicializa la base de hechos con la situación propuesta (paciente de más de 12 años que acude por causa ginecológica con tiempo de evolución mayor de 73h)
b_hechos <- list("Causa_Ginecologica", "Edad_>12a", "TiempoEvolucion_>73h")y se ejecuta el motor del SE:
# Se lanza la ejecución del motor del Sistema Experto
AlgoritmoSE(b_hechos, b_conocimiento)El resultado proporcionado por el algoritmo es un triaje de valor \(4\). Es decir, el tiempo de espera máximo para recibir atención médica debería ser inferior a \(60\) minutos. La Tabla ?? muestra el proceso realizado por el algoritmo en cada iteración.
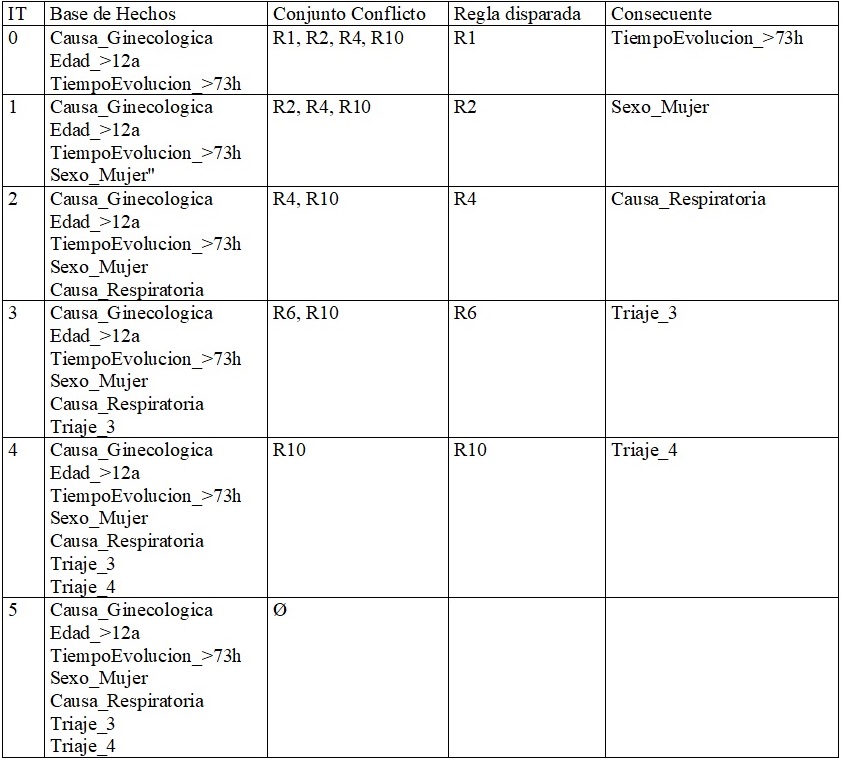
Como puede observarse, el algoritmo finaliza tras \(5\) iteraciones, al alcanzar un conjunto conflicto vacío, dando como resultado un valor de \(4\) para el triaje. A continuación, se describe el proceso ejecutado en cada una de las iteraciones.
Iteración 0: la BH se inicializa con las condiciones establecidas en el ejemplo de consulta médica considerado, es decir,
Causa_Ginecologica,Edad_>12ayTiempoEvolucion_>73h. En el conjunto conflicto se incluyen aquellas reglas que podrían ser lanzadas con los elementos contenidos en la BH, es decir, las reglas R1, R2, R4 y R10. Se dispara la regla R1, al ser la primera de la lista de reglas del conjunto conflicto. El consecuente de la regla disparada (TiempoEvolucion_>73h) se añade a la BH para la siguiente iteración, aunque en este caso no es necesario porque ya lo contiene. La iteración finaliza estableciendo como conclusión el consecuente de la regla disparada, es decir,TiempoEvolucion_>73h.Iteración 1: el conjunto conflicto se inicializa con las reglas que podrían ser lanzadas, excluyendo las ya ejecutadas (R1), a partir de los elementos incluidos en la BH tras la iteración anterior, es decir, las reglas R2, R4 y R10. Se lanza la primera de las reglas del conjunto conflicto, es decir, R2. El consecuente de la regla disparada (
Sexo_Mujer) se añade a la BH. La iteración finaliza estableciendo como conclusión el consecuente de la regla disparada, es decir,Sexo_Mujer.Iteración 2: el conjunto conflicto se inicializa con las reglas que podrían ser lanzadas, excluyendo las ya ejecutadas (R1 y R2), a partir de los elementos contenidos en la BH tras la iteración anterior, es decir, las reglas R4 y R10. Se lanza la primera de las reglas del conjunto conflicto, es decir, R4. El consecuente de la regla disparada (
Causa_Respiratoria) se añade a la BH. La iteración finaliza estableciendo como conclusión el consecuente de la regla disparada, es decir,Causa_Respiratoria.Iteración 3: el conjunto conflicto se inicializa con las reglas que podrían ser lanzadas, excluyendo las ya ejecutadas (R1, R2 y R4), a partir de los elementos contenidos en la BH tras la iteración anterior, es decir, las reglas R6 y R10. Se lanza la primera de las reglas del conjunto conflicto, es decir, R6. El consecuente de la regla disparada (
Triaje_3) se añade a la BH. La iteración finaliza estableciendo como conclusión el consecuente de la regla disparada, es decir,Triaje_3.Iteración 4: el conjunto conflicto se inicializa con las reglas que podrían ser lanzadas, excluyendo las ya ejecutadas (R1, R2, R4 y R6), a partir de los elementos contenidos en la BH tras la iteración anterior, en este caso únicamente R10. Se lanza por tanto la regla R10. El consecuente de la regla disparada (
Triaje_4) se añade a la BH. La iteración finaliza estableciendo como conclusión el consecuente de la regla disparada, es decir,Triaje_4.Iteración 5: el conjunto conflicto queda vacío, al no ser posible incluir en él reglas no disparadas aún y que pudieran ser ejecutadas a partir de los elementos contenidos en la BH. Por tanto, el algoritmo finaliza concluyendo como resultado el consecuente de la última regla lanzada, es decir,
Triaje_4.
La implementación del algoritmo, las reglas y el modelado considerado para este caso de estudio es una simplificación intencionada del problema, con el único objetivo de facilitar su comprensión desde una perspectiva académica y docente.
En un escenario de aplicación real, el volumen y la complejidad de las reglas suele ser mucho mayor, considerando además la posibilidad de incorporar otras características que permitieran modelar de un modo más completo el estado de salud del paciente y su motivo de consulta.
Actualmente son innumerables los ámbitos donde la aplicación de un SE puede ser de ayuda. En este caso de estudio el objetivo ha sido facilitar y mejorar el proceso de triaje del nivel de urgencia en el ámbito pediátrico en atención primaria. Pero, en este mismo contexto, podría valorarse su uso como herramienta de apoyo para, por ejemplo, el diagnóstico de enfermedades o la prescripción de tratamientos.
La tecnología actual y los lenguajes de programación como R facilitan la implementación de los SE de un modo rápido y sencillo. Por tanto, pueden ser considerados como herramienta de ayuda para situaciones en las que aplicar conocimiento experto de forma automatizada resulte clave para la solución de problemas.