Capítulo 4 Ética en la ciencia de datos
Mónica Villas\(^{a}\) y Bilal Laouah\(^{b}\)
\(^{a}\)OdiseIA
\(^{b}\)Alexandria Business Solutions Based on Data
4.1 ¿Qué es la ética?
La ética es una subdisciplina de la Filosofía que estudia de manera sistemática el comportamiento humano desde las nociones del bien y del mal y en relación con la moral. Ambas disciplinas están muy relacionadas, pero son diferentes. La moral tiene un carácter normativo y prescriptivo: orienta las acciones de acuerdo con algún marco de valores específico (costumbres, creencias, códigos tradicionales, normas no escritas, etc.). Por el contrario, la ética está por encima de cualquier orientación particular, es decir, no se basa en ningún código de mandatos y prohibiciones concreto, sino que pretende establecer los principios a partir de los cuales evaluar las acciones y decisiones. La ética es Filosofía práctica, por eso no transmite juicios, sino que enseña a juzgar.
Las dos preguntas fundamentales que ha tratado de responder la ética a lo largo del tiempo son: ¿qué debemos hacer? y ¿qué es valioso en la vida? La primera pregunta promueve el razonamiento ético, mientras que la segunda sirve para establecer el marco de valores desde el cual juzga y razona el sujeto ético. Desde una perspectiva histórica, Aristóteles es considerado el primer autor occidental en haber sistematizado la ética. Su tratado es comúnmente conocido bajo el título de Ética a Nicómaco.
Este capítulo se centra en la ética aplicada, que es la utilización de la ética en la práctica. Algunos ejemplos de ética aplicada son la ética profesional (o deontología), la bioética o la ética medioambiental. La ética aplicada a la ciencia de datos hace referencia a la reflexión que debe acompañar a la toma de decisiones en el contexto de la praxis profesional de los científicos de datos; se puede considerar, por tanto, una concreción de la ética profesional. Y es que los científicos de datos tienen que tomar decisiones a lo largo del ciclo de vida de un proyecto de datos que pueden tener consecuencias sobre las personas. Algunos procesos que pueden ser fuente de dilemas éticos son: la recopilación de datos, su transformación, la definición de objetivos que se persiguen, el uso de algoritmos y la explicación de los resultados. Estos pasos se pueden ver de manera detallada en el Cap. 3. En todos estos pasos, el científico de datos debe usar su pensamiento crítico y tomar decisiones éticas. Así, por ejemplo, si el propósito es automatizar algún proceso, deberá reflexionar y anticipar los posibles impactos negativos que pueden derivarse ya que, si este proceso no se realiza adecuadamente, la toma de decisiones automáticas puede perpetuar algunos de los problemas éticos como son los sesgos. Para ser más específicos: supóngase que se quieren automatizar las contrataciones laborales. Para ello, el científico de datos necesita desarrollar un algoritmo que seleccione a los mejores profesionales para su compañía. Pues bien, algunas cuestiones que debe valorar son las siguientes: primero tiene que entender qué significa “los mejores profesionales” y definir los atributos que los representan. Después, tiene que buscar datos históricos de la compañía, recopilarlos y estar seguro de que esos datos cumplen con la normativa de privacidad establecida, especialmente si la compañía reside en Europa. Aquí, el científico de datos debe pensar en temas como la procedencia de los datos, ¿cuál es la fuente?, ¿a quién pertenecen los datos?, ¿están los datos anonimizados para que no se pueda identificar a una persona de manera unívoca?, y algunas preguntas similares referidas a la privacidad. Seguidamente, tendrá que asegurarse de que se tiene una muestra de casos cuyos atributos (edad, profesión, experiencia, raza, género, procedencia geográfica, etc.) no tienen sesgos; es decir, que, por ejemplo, el porcentaje de personas de una determinada raza, o edad, o sexo, etc. no es significativamente distinto del que hay en la población de la cual se tomó la muestra. En definitiva, debe asegurarse de que la muestra que tiene es suficientemente representativa de la población con la que va a trabajar y, si no es así, tenerlo en cuenta a la hora de analizar y comunicar los resultados. Además, ha de tener cuidado con los datos personales, como género, edad, raza, etc., dado que, en algunos casos de uso, la toma de decisiones no debería tener en cuenta estos atributos porque podrían inducir a prácticas discriminantes, alejadas de los estándares éticos. Como se puede ver en este sencillo ejemplo, el científico de datos tiene que tomar decisiones, no solo técnicas, que influyen en el resultado de su trabajo y que pueden afectar a otras personas. Generalmente, los científicos de datos suelen ser profesionales que provienen del mundo técnico, de carreras tecnológicas o relacionadas con las Matemáticas y, a diferencia de otros itinerarios de corte humanista, la presencia de la ética es menos frecuente, razón por la cual conviene fomentar la sensibilización respecto a estas cuestiones.
Mientras que para los profesionales de la salud existen códigos deontólogicos bien establecidos y organismos que regulan la práctica de acuerdo a los mejores estándares comportamentales, no existe una guía común para el científico de datos en que se describa cómo debe comportarse. A pesar de todo, la guía de buenas prácticas que publica la asociación ACM (Association for Computing Machinery) puede servir de inspiración, si bien, al tratarse de meras recomendaciones, sigue siendo insuficiente para orientar éticamente su comportamiento.
4.2 Los principios éticos
Un principio no es ni más ni menos que aquello que permite preservar los derechos y libertades de las personas, sin frenar la innovación tecnológica (Villas & Camacho, 2022). La mayoría de los principios se pueden agrupar en cuatro grandes categorías: autonomía, justicia, evitar daños y generar beneficios. Algunos ejemplos de principios que se pueden clasificar en alguna de estas categorías son: transparencia, explicabilidad, privacidad, accesibilidad o equidad. Aunque no hay aún un acuerdo a nivel mundial sobre cuáles deberían ser los principios claves de la inteligencia artificial (IA), sí que se están desarrollando proyectos supranacionales como el de la UNESCO,14 que ha sido firmado recientemente por todos sus miembros.
Desde principios de 2010, el crecimiento de la ciencia de datos ha sido exponencial y ha comenzado a usarse en todas las industrias de manera sistemática, entre otras cosas gracias al Big Data. Actualmente, se dispone de más datos que nunca y solo se analiza un 5% de ellos. Además, se han producido enormes mejoras en la computación con el surgimiento de nuevos procesadores y también han ocurrido grandes cambios en el área de la algoritmia, teniendo disponibles muchos más algoritmos que nunca, lo que facilita su reutilización. Por ello, la demanda de científicos de datos que conviertan dichos datos en información clave para las empresas ha crecido enormemente en los últimos años.
Asimismo, desde 2016, distintos organismos, asociaciones, empresas y gobiernos han publicado numerosos documentos, donde se resalta la importancia de la necesidad de principios éticos para la ciencia de datos. Google, IBM y Amazon, en el ámbito de las empresas privadas, publicaron sus principios éticos en el 2018. También son muy conocidos los principios de Asilomar de 2016 o la declaración de Toronto de 2017. La mayoría de estos documentos están desarrollados por perfiles multidisciplinares: científicos de datos, abogados o expertos en ética, que resaltan la importancia de tener en cuenta los principios éticos en la toma de decisiones automáticas cuando se utiliza la ciencia de datos.
En definitiva, las cuestiones éticas se están incorporando poco a poco en los proyectos de ciencia de datos en todo el mundo, siendo la regulación europea publicada en abril de 2021 un ejemplo a seguir. Esta regulación, diseñada a lo largo de tres años, parte de un primer documento en 201815 que fue liderado por un grupo de expertos de todos los países miembros: HLEGAI (High Level Expert Group Artificial Intelligence). A partir de este primer documento se publicaron otros incluyendo los comentarios y mejoras sugeridas por la sociedad civil, instituciones públicas, empresas e instituciones académicas, hasta, finalmente, publicarse, en abril de 2021, el actual documento de regulación de IA.
En el actual documento regulatorio, se eligió un enfoque basado en riesgos:
Riesgo inaceptable, como el uso de aplicaciones de social scoring o de imágenes para procesos de administración de justicia.
Riesgo alto, como el uso de aplicaciones de contratación o médicas, que deberán ser supervisadas por organismos designados antes de su publicación.
Riesgo medio, como el uso de aplicaciones en las que hay que incluir las explicaciones necesarias (dependiendo del tipo de algoritmo de que se trate) para que el usuario pueda entender el proceso de toma de decisiones.
Riesgo bajo, para cualquier otro tipo de aplicación.
En el resto del mundo, el progreso en este tipo de regulación está siendo algo más lento, aunque países como Estados Unidos, que hasta ahora no habían puesto el foco en este tipo de regulaciones, están empezando a trabajar en ello desde finales de 2021. Por otro lado, China, conocida mundialmente por su falta de respeto a la privacidad, está empezando a dar algún paso en esta área y comenzando a cambiar su política en este sentido. Como ejemplo, en marzo de 2022, ha lanzado una regulación en la que las empresas tienen que informar mejor a los usuarios sobre sus algoritmos de recomendación. En definitiva, parece que la necesidad de la ética para proyectos de ciencia de datos está avanzando poco a poco en todas las geografías, y Europa es, por el momento, un ejemplo a seguir.
Llegados a este punto, conviene distinguir entre regulaciones legales y principios éticos. Generalmente, las regulaciones legales son coercitivas y su incumplimiento puede tener consecuencias punitivas para quienes no las ratifican e implementan. Estos principios legales, para que sean legítimos, deben fundamentarse e inspirarse en ciertos valores éticos. Ahora bien, es imposible e indeseable regular legalmente todos los aspectos del comportamiento humano, de ahí la necesidad de compartir un marco de valores. La ética permitirá al científico de datos considerar cuál es la mejor decisión cuando exista un vacío legal. El razonamiento ético implica, pues, asumir la responsabilidad de pensar de manera autónoma.
Ahora bien, dado que no hay un acuerdo a nivel mundial sobre cuáles son los principios éticos más importantes para la ciencia de datos, en este capítulo se han seleccionado la equidad y la explicabilidad, por estar entre los que más deben tener en cuenta los expertos en ciencia de datos. Además, son dos de los principios en los que se centra la regulación europea.
4.3 Equidad: la importancia de los sesgos
El sesgo se puede definir como el resultado de dar un peso desproporcionado a favor o en contra de una persona o cosa en comparación con otra, y normalmente de manera injusta. El término “equidad” se utiliza precisamente para tratar de que las decisiones no estén afectadas por esos sesgos. Si se analiza la literatura al respecto, se pueden encontrar multitud de tipos de sesgos. En la ciencia de datos, cuando se habla de sesgo, generalmente se hace referencia a los sesgos algorítmicos. Estos, según la RAE, son “errores sistemáticos en los que se puede incurrir cuando, al hacer muestreos o ensayos, se seleccionan o favorecen unas respuestas frente a otras”.
Este sesgo algorítmico puede darse en cualquiera de los pasos que lleva a cabo el científico de datos (véase Cap. 2).16 En la Fig. 4.1 donde se representan los distintos pasos a la hora de diseñar un algoritmo de ciencia de datos, se puede ver cuáles son los momentos críticos en los que, sin percibirlo, se puede caer en este tipo de sesgo. En primer lugar, un sesgo en la adquisición de los datos, partiendo de muestras que ya lo tengan. En este punto se encuadran, por ejemplo, los sesgos históricos o los sesgos de representación. También puede haber sesgos de medida, que son los sesgos algorítmicos derivados de la selección de las características que se eligen para la construcción del modelo. Además, se pueden presentar sesgos en el momento del despliegue, denominados sesgos de implementación, que suceden cuando el contexto en el que se despliega el algoritmo es diferente del contexto en que se entrenó.
El estudio detallado de estos sesgos algorítmicos está enfocado a evitar que se aumenten o perpetúen sesgos de cualquier tipo, teniendo en cuenta que los algoritmos tienen como objetivo automatizar y generalizar. Como se veía en la sección anterior, mucha de la regulación que se está desarrollando en Europa va enfocada a mantener el principio de equidad, es decir, a tratar de evitar los sesgos en la toma de decisiones automáticas realizadas por los algoritmos que se diseñan gracias a la ciencia de datos.
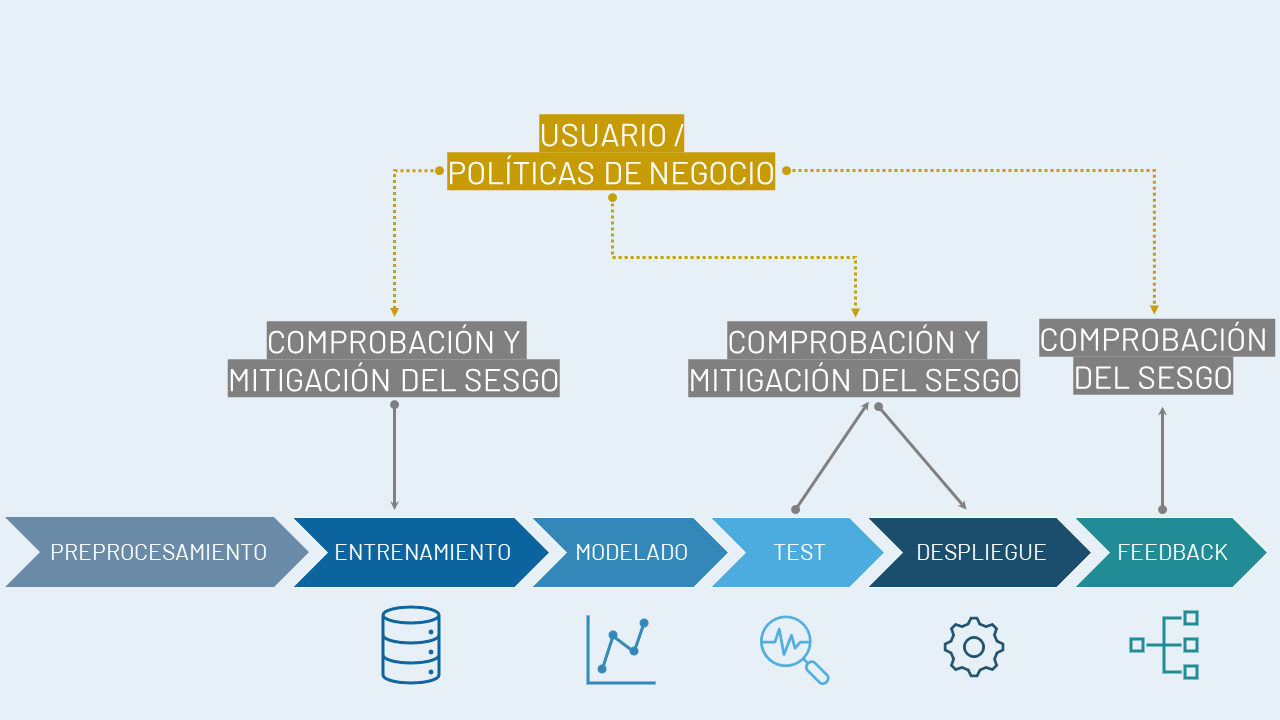
Figura 4.1: Sesgos en el proceso de \(machine\) \(learning\). Fuente: Adaptada de IBM.
Un ejemplo, que muestra la importancia de los sesgos históricos y de representación, es COMPAS (Correctional Offender Management Profiling for Alternative Sanction), una aplicación que da soporte al sistema de justicia americana y que utiliza un algoritmo para evaluar el riesgo potencial de reincidencia de una persona que va a ser juzgada.
COMPAS evalúa, para cada acusado, dos tipos de riesgo: de reincidir y de reincidir con violencia. El algoritmo que utiliza califica de 1 a 10 la posibilidad de que el acusado vuelva a cometer un delito (sin y con violencia). De 1 a 4, el riesgo se califica de bajo; de 5 a 7, medio; y de 8 a 10, alto. Si la persona puede ser reincidente espera a que ocurra el juicio en la cárcel, y, en caso contrario, no tiene que ir a la cárcel hasta que se celebre el juicio. Diversos estudios y organizaciones analizaron los datos y no parecía que hubiera ningún problema de sesgo inicialmente. Sin embargo, la organización PROPUBLICA, con datos de 7.300 personas correspondientes a 2013 y 2014, demostró que la aplicación estaba sesgada. En concreto, demostró que los acusados negros tenían muchas más probabilidades que los acusados blancos de ser clasificados, incorrectamente, como de riesgo de reincidencia elevado, mientras que los acusados blancos tenían más probabilidades que los acusados negros de ser marcados incorrectamente como de riesgo bajo.
El proceso que se siguió fue el siguiente:
- Partiendo del proceso de asignación de un riesgo, se construyó el historial delictivo del acusado.
- Para determinar la raza, se usó la clasificación establecida, de negros, blancos, hispanos y asiáticos.
- Se revisó la definición de reincidencia y cómo se establecían los riesgos en la aplicación de COMPAS.
- Únicamente se analizaron los riesgos para “reincidencia” y “reincidencia con violencia”.
- Se analizaron los índices de reincidencia y de reincidencia con violencia en dos años, así como su distribución por raza.
- Para contrastar la hipótesis de disparidad entre razas en el índice de riesgo, se utilizó una regresión logística que consideraba la raza, la edad, la historia criminal, la reincidencia futura, el grado de los cargos y el género.
- Para evaluar la exactitud del algoritmo se usó una regresión de Cox.
- Se utilizó una muestra de unos 7.300 acusados (de los que se tenía datos de dos años) para analizar la tasa de falsos positivos y falsos negativos.
El modelo logístico concluyó que el factor más predictivo de una puntuación de riesgo de reincidencia más alta era la edad. Los acusados menores de 25 años tenían 2,5 veces más probabilidades de obtener una puntuación más alta que los delincuentes de mediana edad, incluso cuando en el modelo se incluía como variable de control el número de los delitos anteriores, la delincuencia futura, la raza y el género. La raza también se consideró muy predictiva de una puntuación más alta. Si bien los acusados negros tenían tasas de reincidencia más altas en general, cuando se ajustaron por esta diferencia y otros factores, tenían un 45% o más de probabilidades de obtener una puntuación más alta que los blancos. En cuanto al sexo, las mujeres tenían un 19,4% más de probabilidades de obtener una puntuación más alta que los hombres, controlando los mismos factores. Esta conclusión resulta, cuando menos, sorprendente, dado que los niveles de criminalidad de las mujeres eran, en general, más bajos que los de los hombres.
La herramienta predecía bien el riesgo de reincidencia en el 60% de los casos estudiados, pero solo en el 20% de ellos cuando se trataba del riesgo de reincidir con violencia. La Tabla 4.1 resume las principales conclusiones obtenidas en el estudio de PROPUBLICA.
| Casuística en el estudio con datos de dos años | Resultados en porcentaje |
|---|---|
| A los acusados de raza negra se les asignaba un riesgo más alto de reincidencia |
Raza negra: 45% Raza caucásica: 23% |
| A los acusados de raza blanca se les asignaba un riesgo más bajo de reincidencia que a los de raza negra |
28% a los de raza blanca 48% a los de raza negra |
| Mayor asignación de riesgo de reincidencia a las personas de raza negra | 77% más de riesgo de reincidir a las personas de raza negra que a las de raza blanca |
| Se determinó que las variables que tenían mayor importancia para la asignación de riesgo de reincidencia eran la edad, la raza y el género |
< 25 años tenía 2,5 veces más de probabilidad de ser asignado un riesgo alto 45% si eran de raza negra Casi un 20% si la persona era mujer |
En este caso, el problema del sesgo tiene como consecuencia que personas que no reincidirían permanezcan en la cárcel al asignárseles un índice de reincidencia más alto que el que realmente les corresponde, y que personas que sí podrían reincidir quedarían en libertad por asignárseles un índice más bajo del que realmente tienen.
Hay multitud de ejemplos publicados respecto al tema de los sesgos. Una de las mejores referencias es O’Neil (2016), que recopila una gran variedad de casos en la que los sesgos pueden llevar a toma de decisiones erróneas y no equitativas.
4.4 ¿Es necesaria la explicabilidad?
La explicabilidad es otro de los principios clave de de la propuesta europea de IA confiable y, sin duda, va a ser clave en los próximos años en cuanto la regulación europea de IA entre en vigor.
XAI (Explainable AI) es un término que acuñó DARPA (Defense Advanced Research Project Agency) en el año 2017 y que agrupa dentro del término “explicabilidad” no solo el concepto de interpretabilidad para los algoritmos de machine learning, sino también los aspectos de la Psicología que están relacionados con proporcionar explicaciones, como se puede ver en la Fig. 4.2. No se trata únicamente de entender la toma de decisión del algoritmo, sino también de dar una expliación adecuada de por qué se toma dicha decisión, en función del tipo de usuario. Si se considera, por ejemplo, de un algoritmo que selecciona imágenes cuando contienen un posible tumor, no serán las mismas explicaciones las que necesitará un científico de datos que un médico. Para el científico de datos será mucho más útil revisar las métricas propias del algoritmo (exactitud, precisión, sensibilidad, etc.) y, además, saber cuáles de los atributos de entrada del algoritmo han tenido más peso en la decisión. En cambio, al médico lo que le interesará será una explicación menos técnica, más cualitativa, en la que se le explique con detalle, por ejemplo, por qué se seleccionó esa imagen frente a otras, mencionando el tamaño, la forma o características de la imagen, aspectos con los que están familiarizados los profesionales médicos.
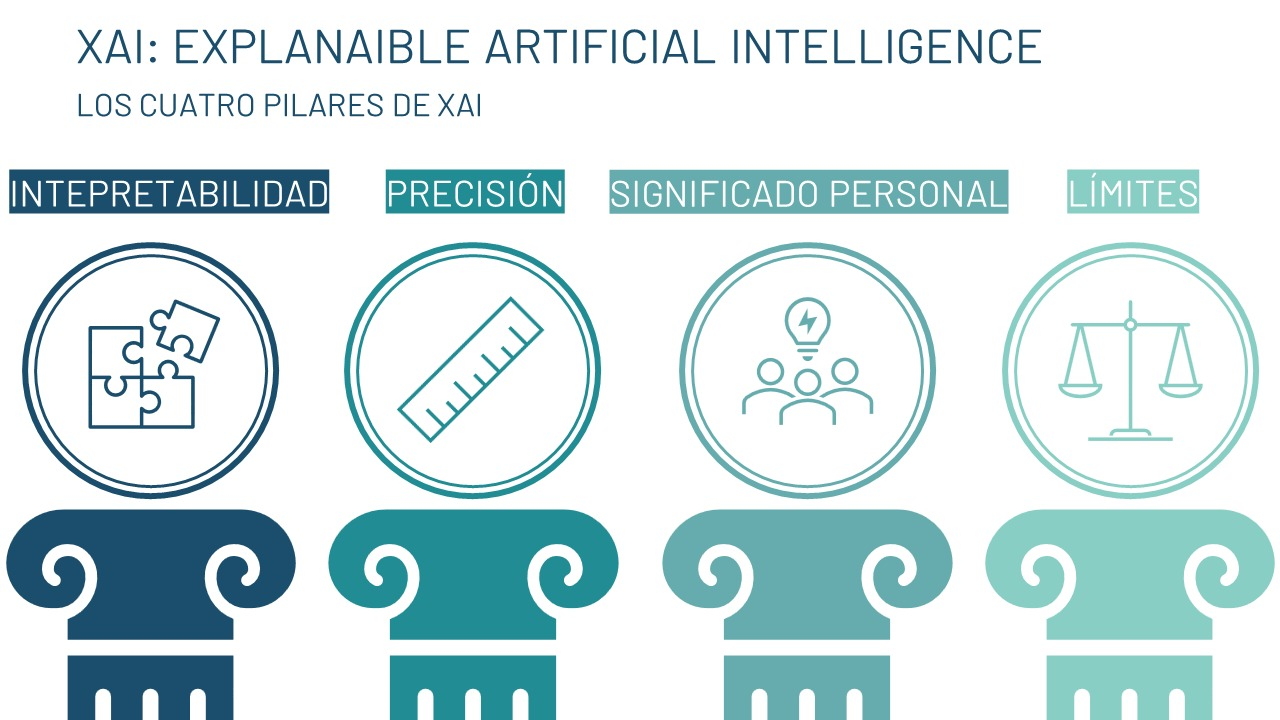
Figura 4.2: Explicabilidad según DARPA.
Los algoritmos pueden clasificarse en algoritmos de caja blanca o transparente (aquellos que son fácilmente interpretables) y opacos o de caja negra (los que no son interpretables y que requieren de herramientas adicionales para su interpretación). Normalmente, se tiene que establecer un equilibrio entre la interpretabilidad y la exactitud, dado que son métricas que mantienen una relación inversa (véase Fig. 4.3). A mayor exactitud, menor interpretabilidad, y viceversa. Los algoritmos más interpretables son normalmente los más sencillos, como los algoritmos de clasificación, regresión lineal o los árboles de decisión. Otros, como los modelos de random forest, XGboost o algoritmos de deep learning, son mucho más exactos pero no tan interpretables, lo cual puede llevar a ciertos problemas a la hora de usarlos en la toma de decisiones en las compañías, dado que es más difícil explicar el porqué de la decisión. Cuando las decisiones afectan a áreas clave para las personas (decisiones médicas, de contratación, de concesión de préstamos, etc.) es cuando más relevante resulta proporcionar la explicabilidad adecuada.
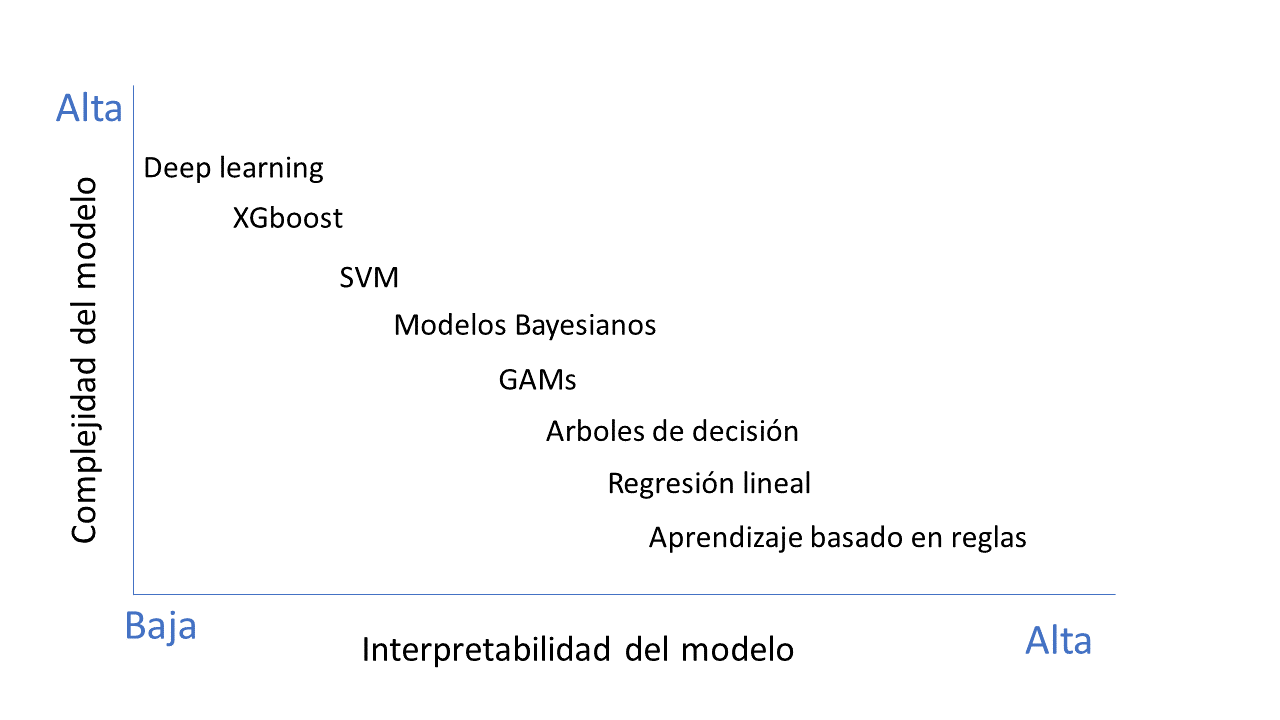
Figura 4.3: Interpretabilidad \(vs.\) exactitud.
Se está avanzando muy rápido en la interpretabilidad de los algoritmos, y desde 2017 se proporcionan distintas técnicas y herramientas que ayudan a ello, como, por ejemplo, las librerías SHAP (SHapley Additive exPlanation) o LIME (Local Interpretable Model-agnostic Explanations), de código abierto. En la mayoría de las ocasiones, se trata de utilizar algoritmos más sencillos que ayuden a explicar otros más complejos como redes neuronales o XGboost.
Hay muchas taxonomías diferentes para la clasificación de los distintos tipos de algoritmos. Una de las más utilizadas clasifica los algoritmos como sigue:
Metodologías globales o locales: cuando el método utiliza una instancia para la interpretabilidad se denomina local y cuando este usa todo el modelo se denomina global.
Metodologías intrínsecas o post hoc: “intrínseca” se refiere a cuando el método es interpretable por sí mismo y post hoc, cuando es necesario usar otros algoritmos más sencillos para explicar los más complejos.
Metologías ligadas al modelo o agnósticas del modelo: las metodologías ligadas al modelo son aquellas que se usan para un tipo de algoritmo concreto, mientras que las metodologías agnósticas permiten trabajar con cualquier tipo de modelo.
Es importante elegir la técnica más adecuada dependiendo del tipo de modelo a interpretar, así como poder combinarlas en aras de conseguir una mejor interpretabilidad. Uno de los mejores libros al respecto que recopila multitud de estas técnicas es Molnar (2020).
4.5 Recursos en R para trabajar en sesgos y explicabilidad
Para un científico de datos es muy relevante conocer las herramientas, tanto open source como comerciales, disponibles para ser usadas en labores de análisis de sesgos o explicabilidad. Todas las herramientas en esta área son relativamente recientes. Han ido surgiendo desde 2018 y siguen evolucionando rápidamente.
En el caso de las herramientas para detectar sesgos, los proveedores que empiezan a incluir estos análisis son Microsoft, IBM, Google, Aequitas, Pymetric y LinkedIn, siendo el resto open source. La mayoría de ellas están abiertas a contribuciones externas y todas ellas utilizan mecanismos para la detección de sesgos, aunque únicamente las de Microsoft e IBM incluyen algoritmos para su mitigación.
En lo relativo a las herramientas sobre explicabilidad, los proveedores más relevantes son Google, IBM, Oracle y H20.ai; el resto son open source. La mayoría de ellas se pueden usar con algoritmos de caja blanca o negra. Respecto a los tipos de explicaciones para distintos usuarios, solo la herramienta de IBM incluye esta funcionalidad. Se puede resaltar también la facilidad con la que H20.ai permite elegir el nivel de exactitud y explicabilidad en el momento del diseño del algoritmo. Para un mayor detalle se pueden consultar dos tablas comparativas sobre herramientas de explicabilidad y de sesgos que se incluyen en Villas & Camacho (2022).
Algunas de estas herramientas comerciales incluyen implementaciones en Python o R, de ahí la importancia de revisarlas inicialmente antes de recurrir a otro tipo de recursos.
Recursos en R para equidad:
La librería
fairness:17 18 incluye algoritmos para detectar el sesgo, pero también para mitigarlo. Explica las distintas métricas usadas para medir la equidad (paridad demográfica, paridad proporcional, paridad predictiva, etc.) y permite crear las distintas métricas y visualizarlas. El tutorial emplea los datos de COMPAS.La librería
EDFfair:19 tiene una aproximación distinta, dado que permite al usuario ajustar el nivel de equidad frente al de exactitud, y así mantener el equilibrio requerido. Los detalles pueden verse en Matloff & Zhang (2022).
Recursos en R para explicabilidad:
- Algunas de las herramientas más conocidas en explicabilidad que
merecen mención aparte son SHAP20 y LIME,21 disponibles en R y
en Python y usadas en muchos paquetes comerciales.
shapres una de las librerías más usadas para la explicabilidad. Utiliza los valores de Shapley para poder explicar cualquier tipo de modelo. Los detalles se pueden encontrar en Aas et al. (2021), donde también se proporciona el código.22limees otra de las librerías más usadas para la explicabilidad. Para ello, se ajusta un modelo local alrededor de un punto concreto y lo que hace es estudiar los cambios alrededor de este modelo. Se puede encontrar una explicación detallada, junto con el código necesario,23 en Ribeiro et al. (2016).
-
Matloff & Zhang (2022) hacen una recopilación de 27 librerías
de R, incluyendo
limeyshapr; el código para cada una de ellas puede encontrarse en GitHub.24
-
DALEX(Biecek, 2018) es un paquete de R de reciente creación para ayudar a crear explicaciones partiendo de un modelo (el código también puede encontrarse en GitHub).25
- Esta área está evolucionando mucho en los últimos años, y están surgiendo multitud de técnicas nuevas alrededor de la explicabilidad que van a permitir entender mejor el proceso de decisión de los algoritmos más complejos.
Resumen
La ética, subdisciplina de la Filosofía, es el estudio sistemático del comportamiento humano desde las categorías del bien y del mal. Se trata de una rama aplicada que proporciona métodos basados en la racionalidad crítica para evaluar decisiones y acciones en base a ciertos valores compartidos.
La aparición de las actuales metodologías que propone la ciencia de datos supone un desafío que no puede resolverse únicamente a partir de criterios técnicos, puesto que muchas de las decisiones que se toman en este campo pueden tener repercusiones sobre las personas.
No existe un acuerdo global en relación con los principios que deben regir el comportamiento del científico de datos, pero la numerosa literatura publicada desde 2016 parece estar de acuerdo en que todos ellos pueden agruparse en cuatro categorías: preservar la autonomía humana, generar beneficios, evitar daños y fomentar la justicia.
Este capítulo se centra en los principios clave que señala la regulación europea: equidad y explicabilidad.